
디비 인덱싱 & guid
클러스터 인덱스

테이블을 구성바는 방식은 두가지가있다
- 힙
- 클러스터 형 인덱스
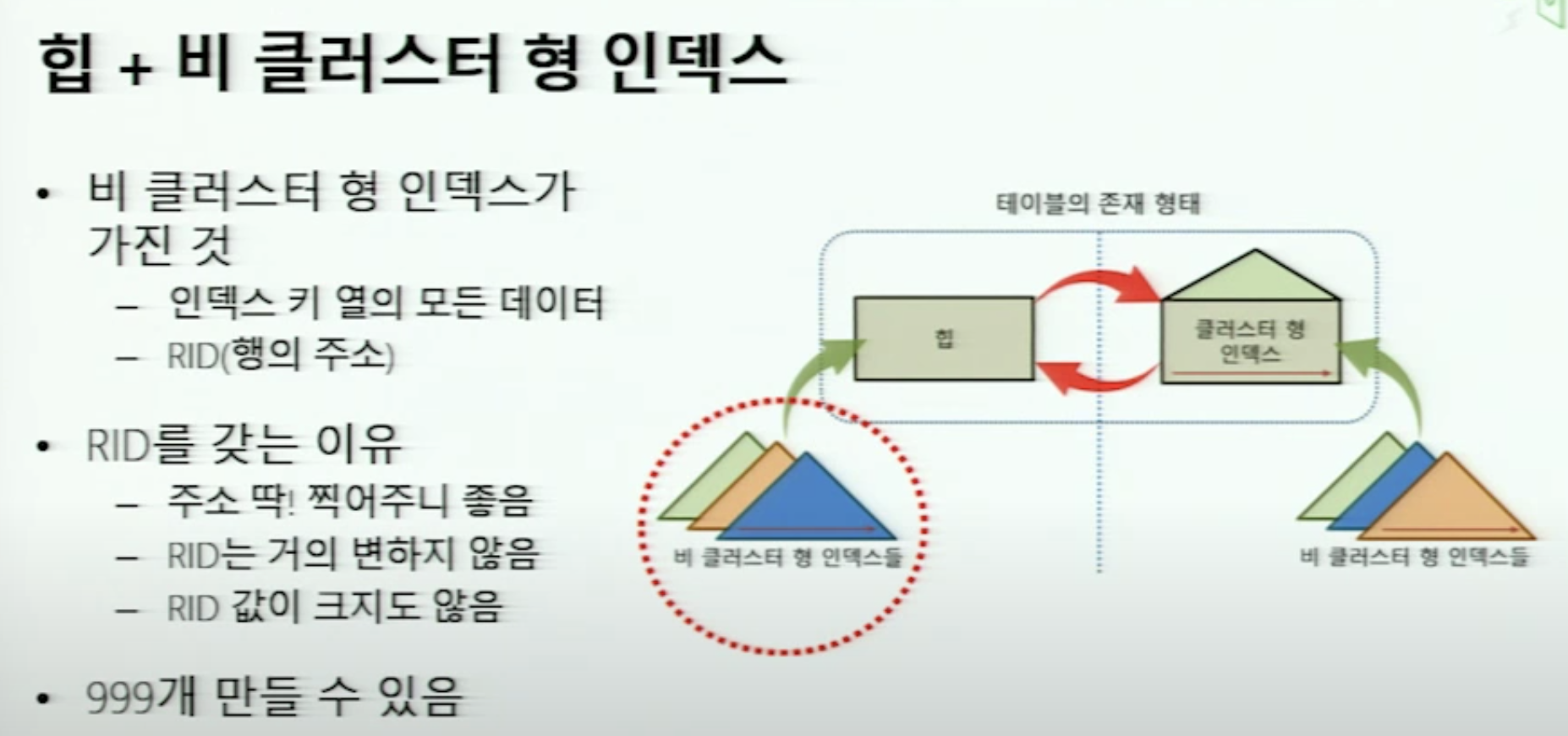
RID는 이 구조에서 언급되는 용어이다.
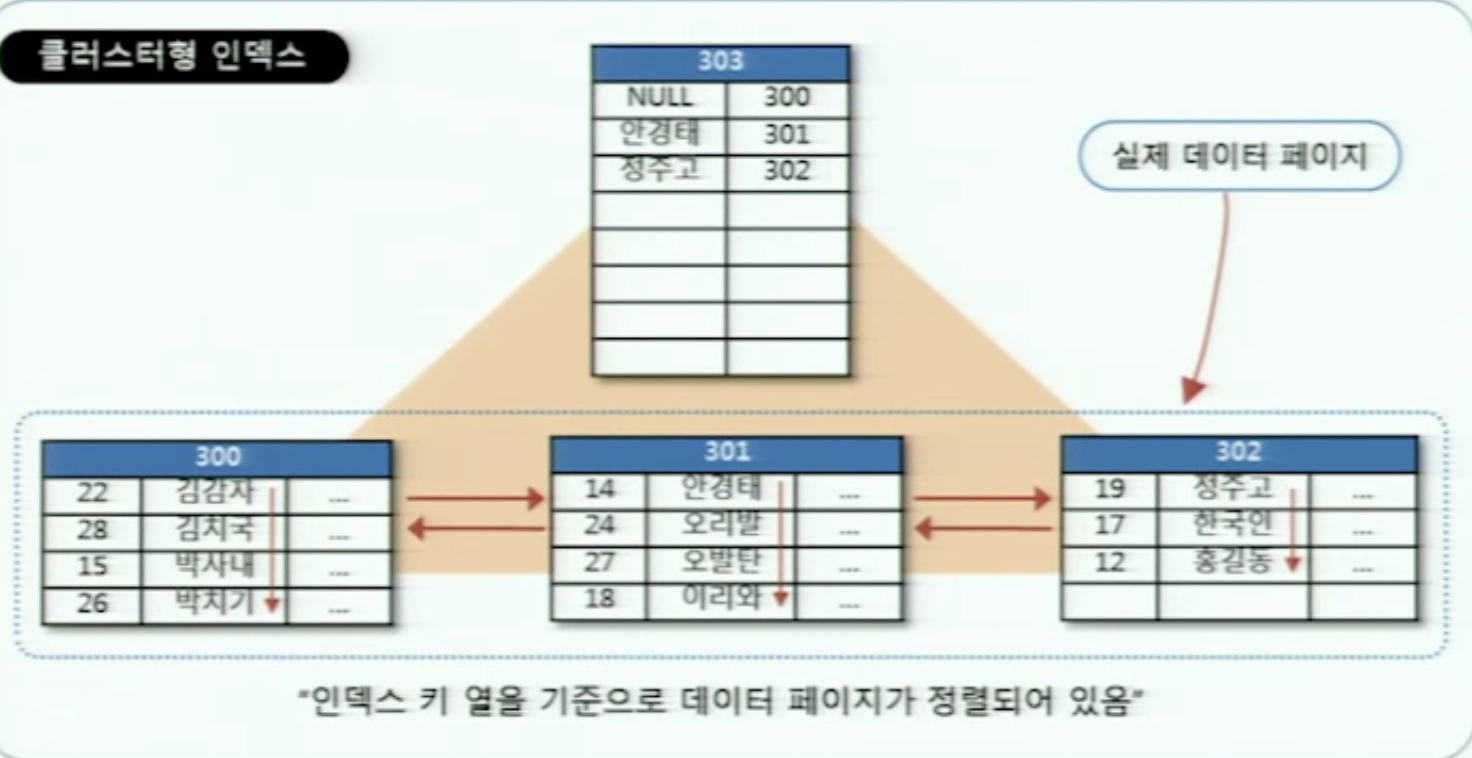
클러스터 형 인덱스
클러스터 형 인덱스는 유니크한 특정 열을 기준으로 테이블이 정렬되어있다.
정렬되어있는 배열을 생각하면 좀 간단해진다.
물리적으로 다 붙어있는건 아니다. 이부분은 가상메모리의 페이징과 비슷한 상황 다 흩어져있음.
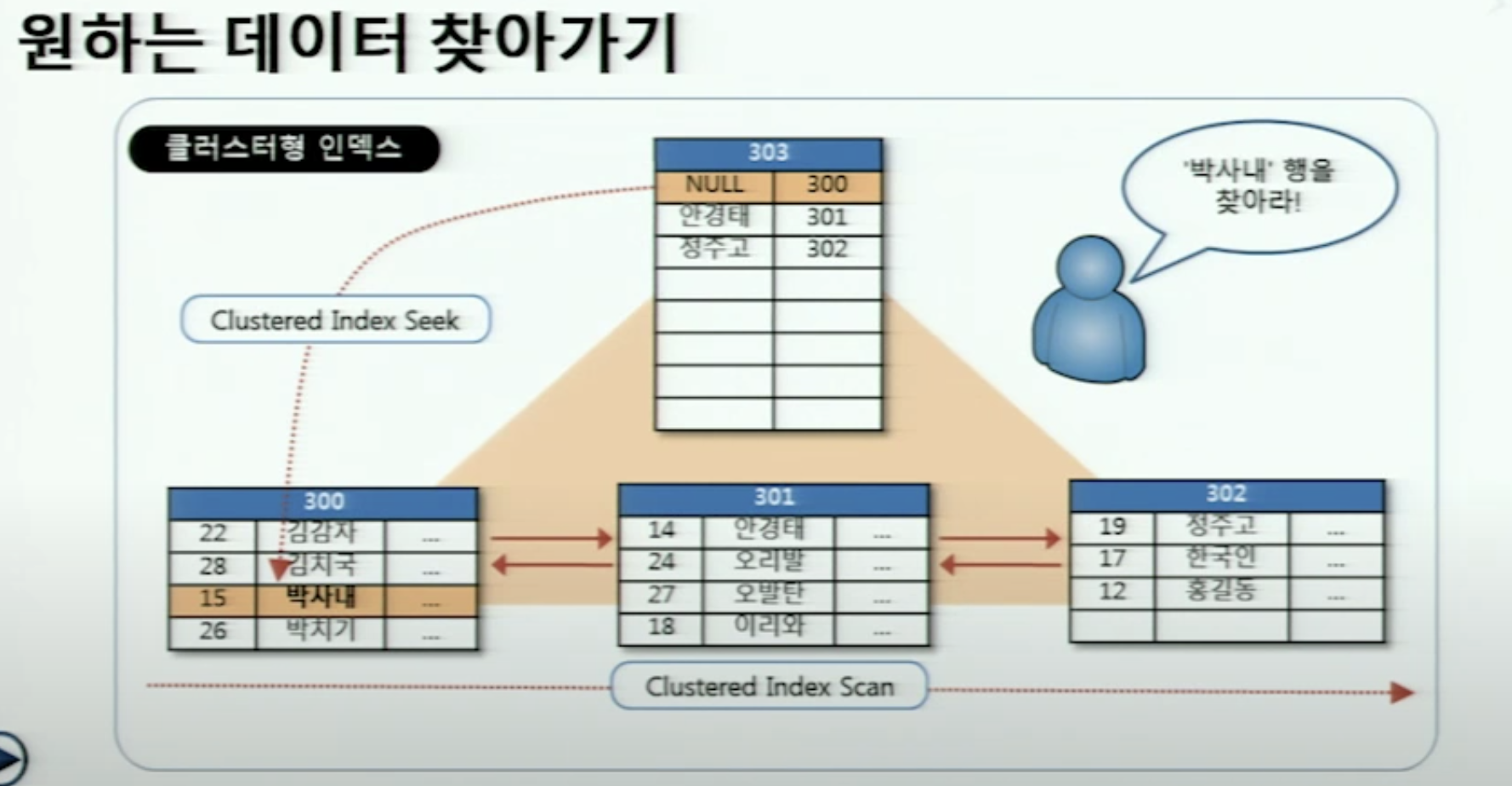
그래서 클러스터형 인덱스로 지정된 컬럼으로 select를하면 속도가 빠르다.
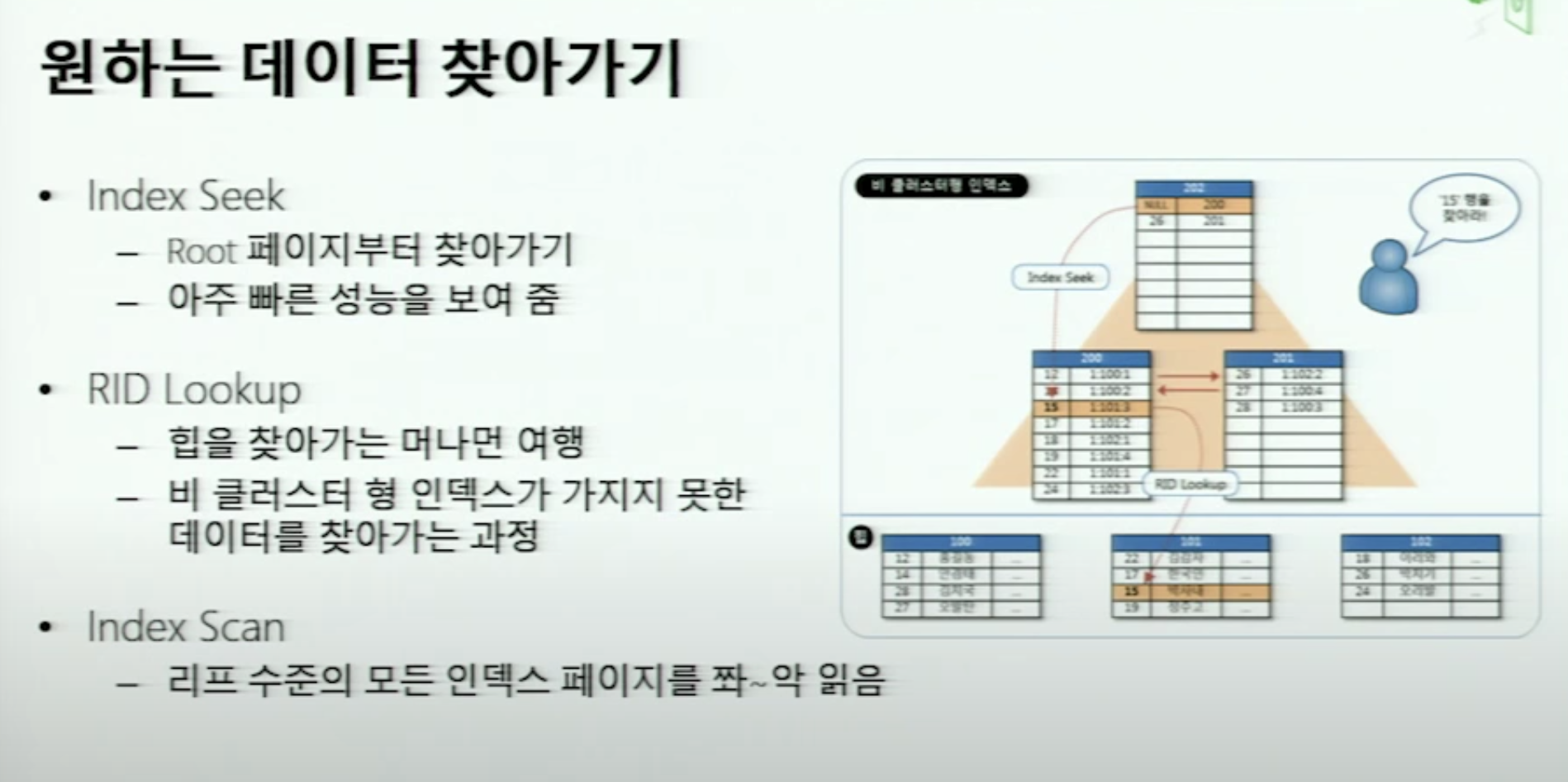
여기서 인덱스를 통해서 해당 행을 찾는걸 index Seek라 한다.
B트리
논 클러스터 형 인덱스
클러스터 형 인덱스로만 검색하지않고 근데 다른 방법으로도 검색시 속도를 높이고 싶어하니 등장한게 비 클러스터 형 인덱스다.
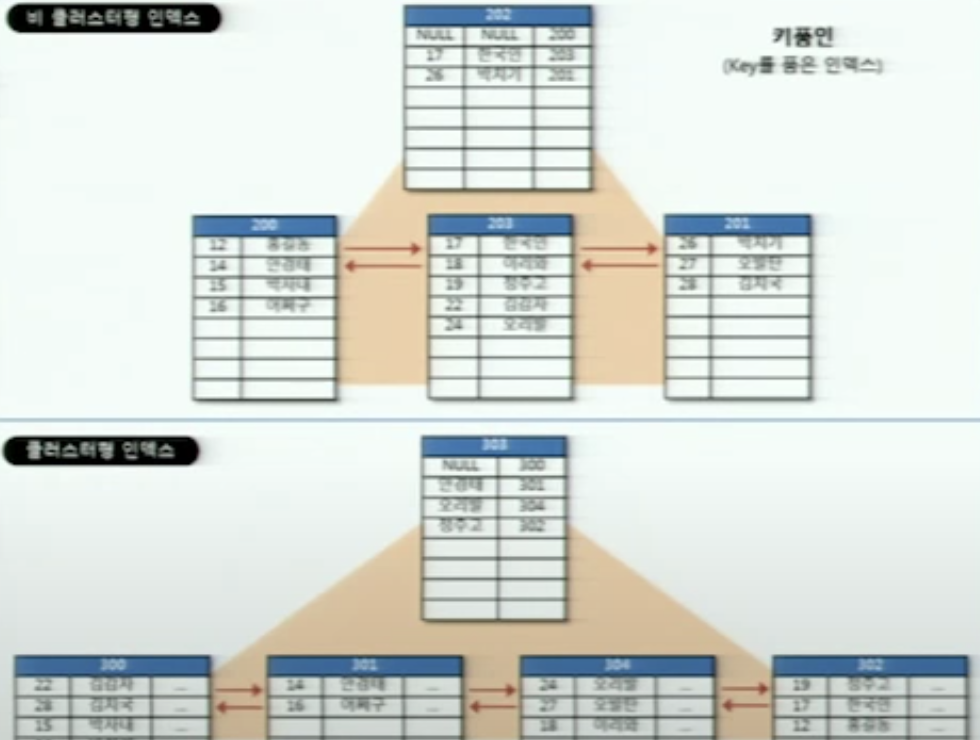
논 클러스터형 인덱스 칼럼을 기준으로 정렬된 페이지를 추가로 가지고 있고 거기에서 pointer 로 테이블의 행을 가르키는 상황.
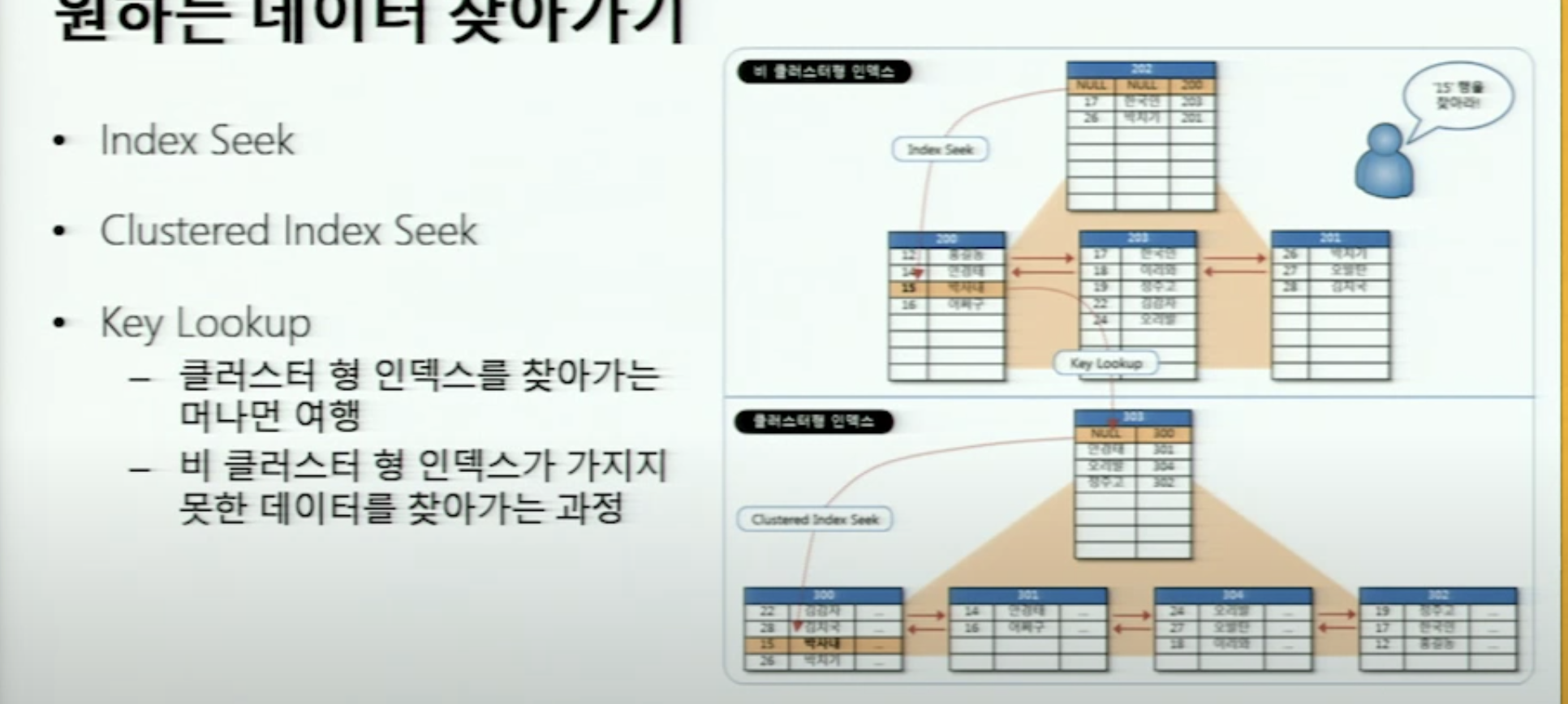
index seek → key lookup → clustered index seek
결국 clustered index를 거치게 되어있다.
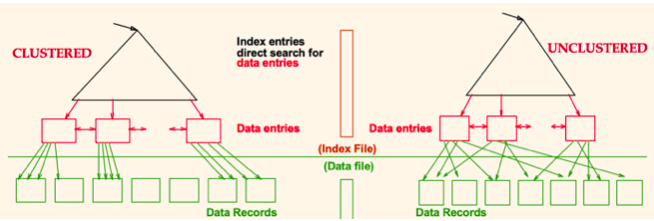
최종정리
insert(lock) : insert의 경우 중간에 들어간다면 말그대로 삽입정렬에서 삽입의 상황이 된다.
그래서 O(n)의 시간이 걸리고 밀리는 행들에 대해서 lock이 모두 걸리기때문에 디비 전체적으로 부하가 생길 수 있다. → clustered index를 기준으로 push_back 마냥 맨 뒤에 추가하는 형식이 가장 이상적
update(lock) : update 의 경우는 클러스터 인덱스의 컬럼값을 바꾸는 경우 정렬이 깨지면서 재정렬을 해야할 수 있다. 이때 insert와 같은 상황이 나오니 결론적으로 클러스터 인덱스의 값은 한번 세팅되곤 바뀌지 않는걸로 해야한다.
select : clustered index를 기준으로 select를 하는게 가장 빠르다. 그다음으로는 논 클러스터 형으로 select
특히 정렬되어있다보니 clusted index 를 기준으로 범위 select를 했을때 성능이 좋다. 논클러스터는 직접하나하나 접근하는 식.
delete : 이또한 중간에 빠지면 전체 정렬을 앞으로 땡기는 등 insert와 비슷한 상황이 발생한다
정말정말 많은 DB에 값이 존재하는 경우는 delete를 바로 시키지 않고 사용하지않는걸 나타내는 컬럼을 세팅해서 걔를 체크해서 따로 점검시간이나 이런때 전체 정렬시키는 방식으로 응용할 수 있다.
GUID
GUID란
보통 primary key를 많이쓰는데 indentity 넣고 insert할때마다 자동으로 1씩 증가하게하는식으로 많이 사용
최근들어 새로운 패턴이 많이 나옴
CQRS라던가 Event Sourcing이라던가
이걸 디자인 패턴에서 보면 Reader Writer가 분리되어있는 패턴
Message queue같을걸 이용해서 writer면 write넣고 메세지가 온다음에 나중에 DB로 넣어주는식
이러면서 DB에 쓰기 작업이 조금 뒤니 Read할때는 비동기가 일어남
Write의 문제가 Write를 할때 lock을 걸게됨.
분산 SQL이 제대로 구축이 안되어 있고그래서 논리적으로 분리를 시키게됨
예를들어 0~1000 까지는 요 DB 1001~ 2000까지 저 DB
이렇게하면서 Lock잡혔을때의 부하를 내리기위해서
그 중하나가 CQRS임
근데 이 나눠진 DB들을 합치고싶을때 primary key가 auto increment면 머지할 방법이 없어서
그리고 이 CQRS, event sourcing에서 메세지 큐에넣을땐 당연히 DB에 아직 안넣었으니 pk 값이 없음
그래서 요새는 GUID(Globally Unique Identifier)많이 씀
충돌이 안나는건아닌데 날일이 거의 없음
얘를 PK로 설정하자.
이때 GUID를 string로 설정하면서 비교연산등에 나오는 성능저하는 10%미만이다.
이렇게하면 합칠때도 merge 충돌이없음.
여기서 고려하는 다른 성능저하가 있는데
merge를 하면서 중간삽입의 문제가 있음.
정렬된 array의 중간삽입 문제가 동일하게 존재
이거를 해결할방법.
PK는 GUID로 사용
그다음에
index id 나 order id같은 칼럼을 추가한다음에 이걸 옛날 방식으로 사용한다
DB는 넣을때 auto increament 순서대로 넣고 primary key는 아까 string으로 넣는다.
merge migrate 할때는 indexid/orderid 칼럼 무시하고 데이터만 뽑아서 새 DB에 insert를 한다.
이 경우엔 10%정도 오버헤드만 존재한다
단점 : 실시간으로 write read 하는 경우에는 힘듬
ORM
ORM은 Object Relational Mapping의 약자
코드에서 기존 SQL을 사용하는 법
- String으로 준비한 다음에 SQL Statement Bind Parameter
- 스트링 붙이기로 합쳐서 한 번에 파라미터로 경우 (보안상 하면 안됨)
이런 것의 단점
DB에는 동적으로 컬럼을 추가할 방법이 없음.
코딩은 OOP로하는데 DB는 서로 다른 패러다임임 그래서 그 사이를 SQL Statement를 사용해서 SQL Engine을 사용하는 식
이러다보니 이를 해결하기 위해 나온게 ORM
하나의 row 데이터를 오브젝트로 보자
Foreing key : 컴포지션 개념
DB table : object class
column : 멤버변수
이렇게 대응되는 개념에서 프로그래머는 object로 정의하고 이 사이간 매핑을 처리하는 레이어를 새로 만든 개념.
사례
- Ruby on Rails
- C# ASP.NET : Entity Framework
단점
- 사람 손으로 짜는 거보다 반드시 최적화된 Statement가 나오지은 않음
- SP 같은 최적화 기술의 혜택을 받기도 힘듬
이후 Entity Framework에대한 내용은 생략