쿠키런: 킹덤, 총 56시간의 긴급 점검 회고
런칭 준비



이런 준비과정들을 통해서
런칭 직후 안정적인 서버를 유지
금요일날 런칭하였고, 첫 주말도 문제없이 지나감
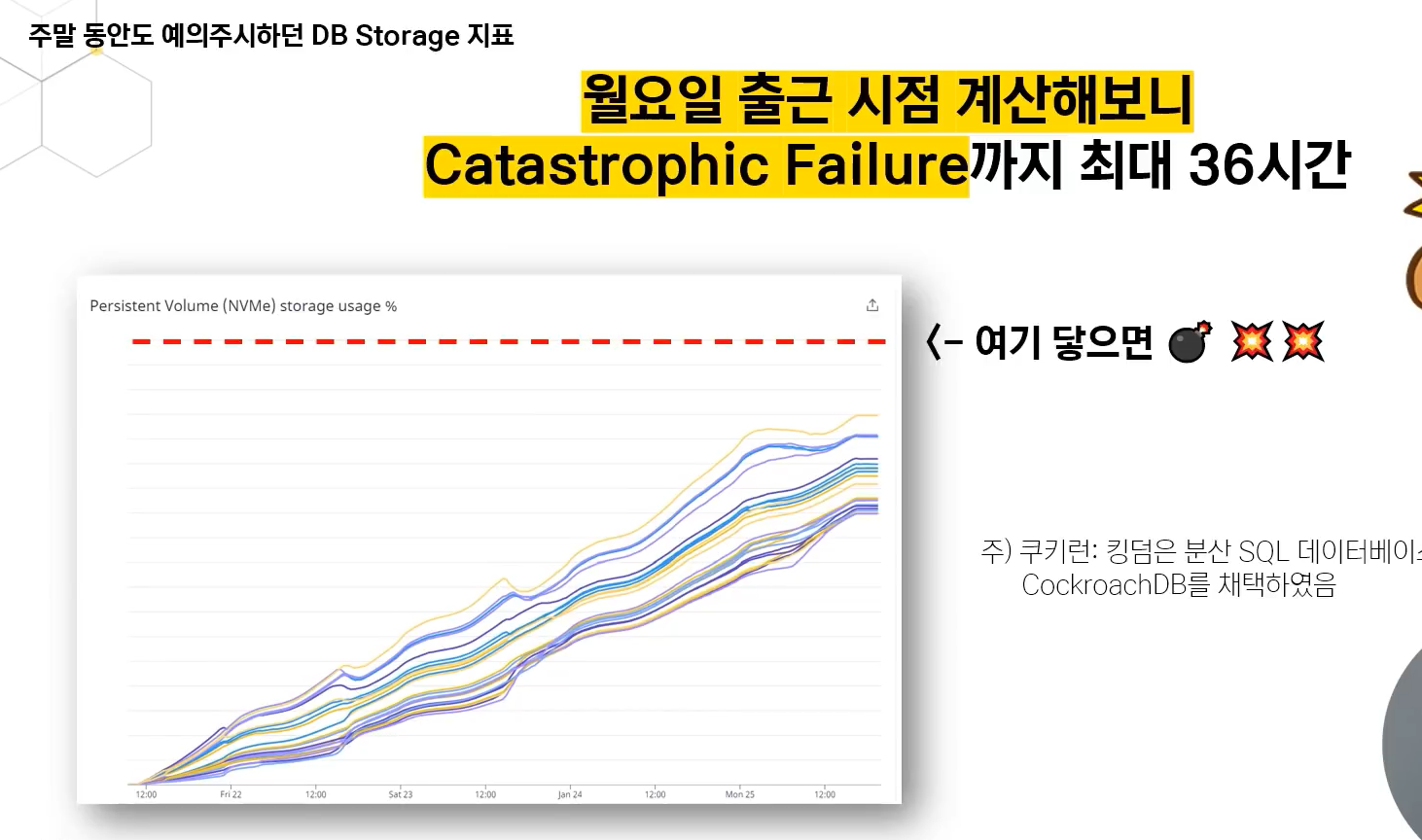
DB용량이 너무 빠르게 차고있었음
catastrophic failure 가 발생할때까지 딱 36시간 남음
분산 DB사용시엔 Horizontal Scale Out 방식으로 대응하나 기울기가 꺽이질 않아서 예상이 잡히지않았고, 유저가 더 들어올지도 모르는 상황이라 disk full 발생시 보험을 두기로 결정


2주간 밤샌 데브옵스 엔지니어가 급하게 대응ㅠㅜ

configuration 이슈가 발생하여 클러스터 비일관성이 발생하여 트랜잭션 처리가 중단됨

데이터가 있는데 클러스터가 데이터를 읽기를 거부.

이러던 와중 AWS 쪽 장애로 Configuration 영향을 받지 않은 노드 한대가 Host Status Failure 로 내려가버림


새 클러스터로 이사를 하기로 결정

바이너리 데이터 규모가 약 7577 기가 바이트로 매우 커서 이 시간이 24시간 정도 걸릴것으로 보여
바이너리 커스텀을 개조

CockroachDB 소스코드를 수정하여 약 10배빠르게 수정하였고 예상보다 더 빠르게 완료되어
총 1시간 30분이 걸림
이 데이터를 분석 인프라에 넘겨 데이터 이사에 사용할 csv파일로 가공

도쿄 리전을 주로 사용하는데
포팅 작업을 진행하며 오후 3시 정도에 도쿄 리전에 있는 모든 r계열 인스터스를 소진함
기존 인프라를 철거해가면서까지 확보하였음

모든 데이터에 대해서 sanity check 를 진행하여 데이터 무결성 체크

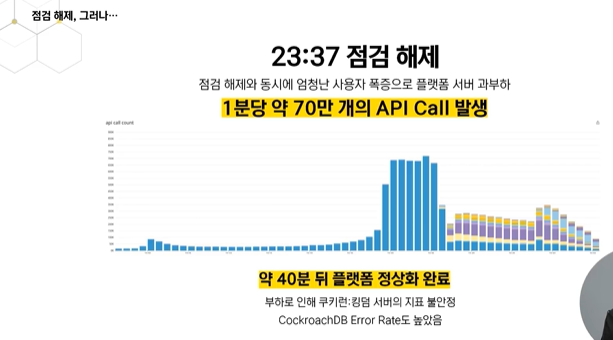
점검 해제로 인해 로그인 요청 부하가 매우 심했음.
분당 70만 api 콜이 오게됨 이때 부하는 역대 최고기록으로 남음
DB에도 부하가 되어 DB 데드락 발생 → 페일 오버 수행
DB쪽도 불안정했음 Error Rate가 많았고, time out error도 많이 발생
오픈 직후부터 cpu 가 엄청 많이 치고있어서 cpu intensive 작업이 동반되는 horiontal 스케일 아웃을하기에도 늦음

이 상황이 지속되다가 새벽 2시 40분 임계치를 넘어 2차 김급 점검 도입

두번째 클러스터 상황을 참고하여 여러가지 최적화를 추가로 적용, 세번째 클러스터를 준비
데이터 이사에 또 2시간 반정도가 소요 DB최적화에 집중하여 총 36시간 반 만에 점검 종료


인프라 작업 프로세스에 새로운 정책을 도입
- 아무리 급한 작업이라도 인프라 관련 작업은 화면쉐어가 필요하고 관전자가 필요함
- 대기열 서버 구축
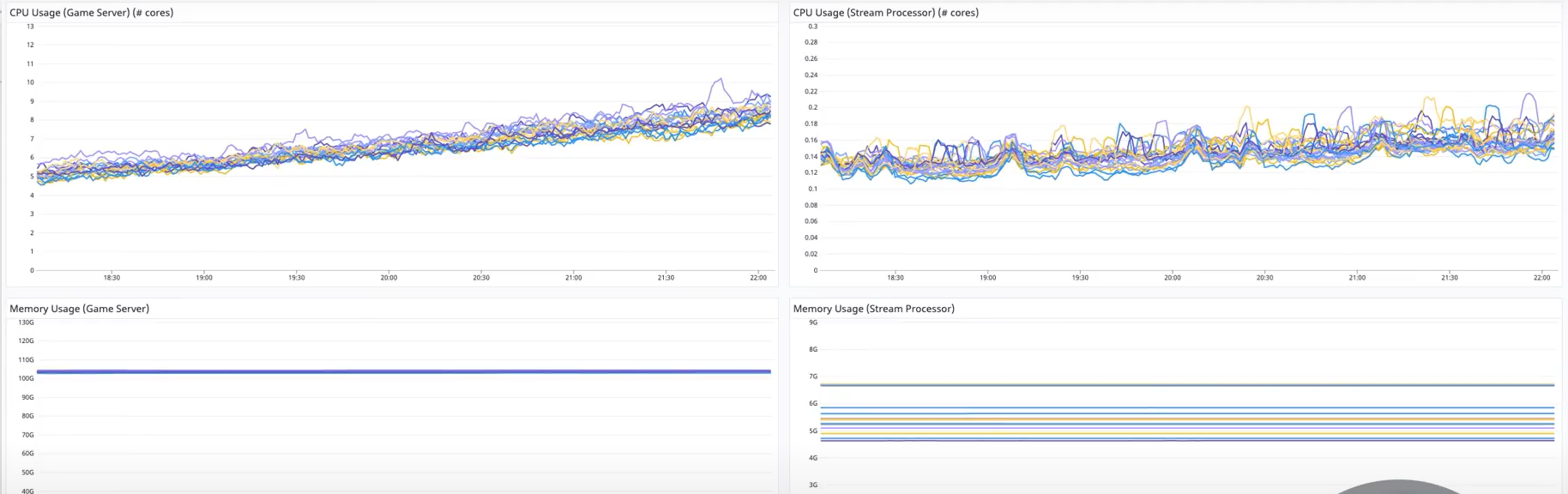
이후 안정화된 수치
이후 안정화되어 정리

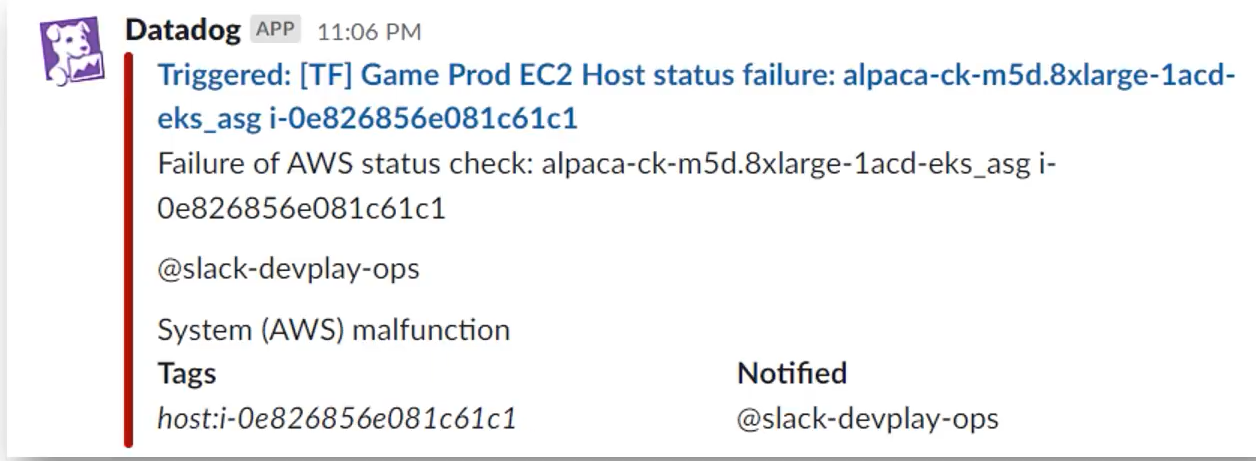
DB 노드 한대가 하드 failure로 이미 내려감
→ 한대정도는 내려갈 수 있지..? 분산 DB를 쓰니까
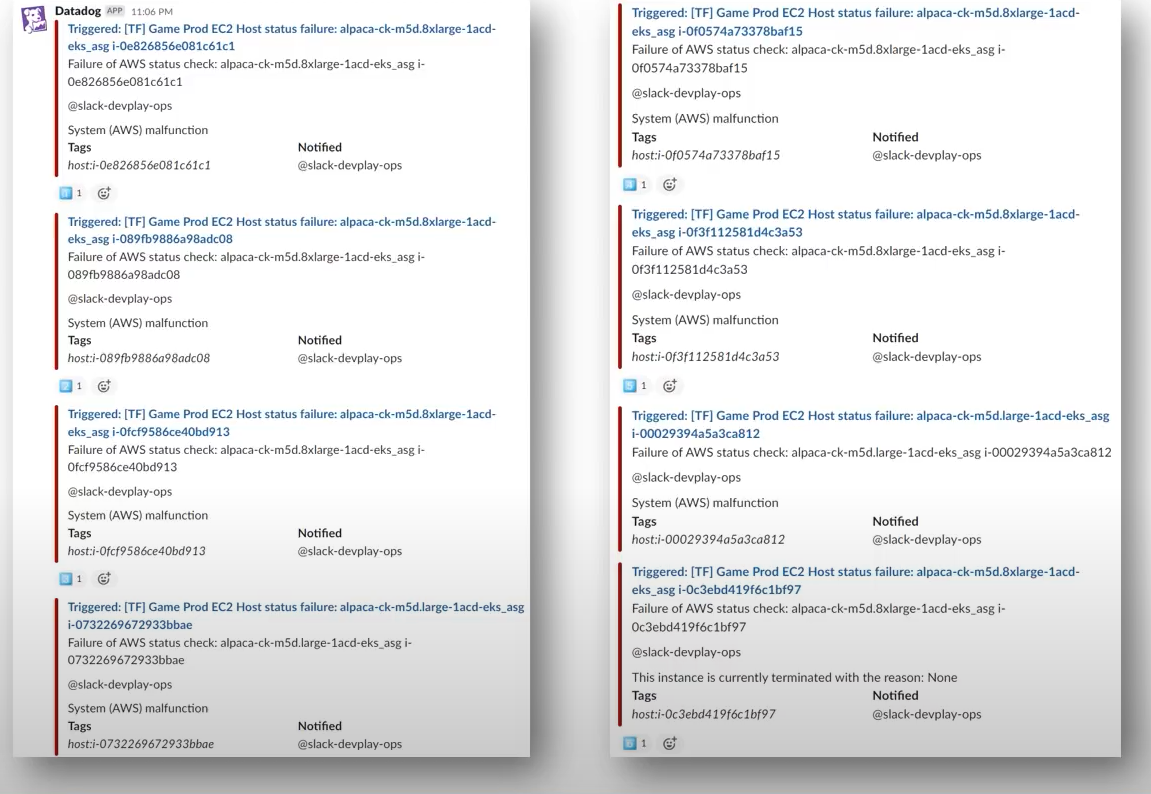
어?
6대 DB노드가 내려감

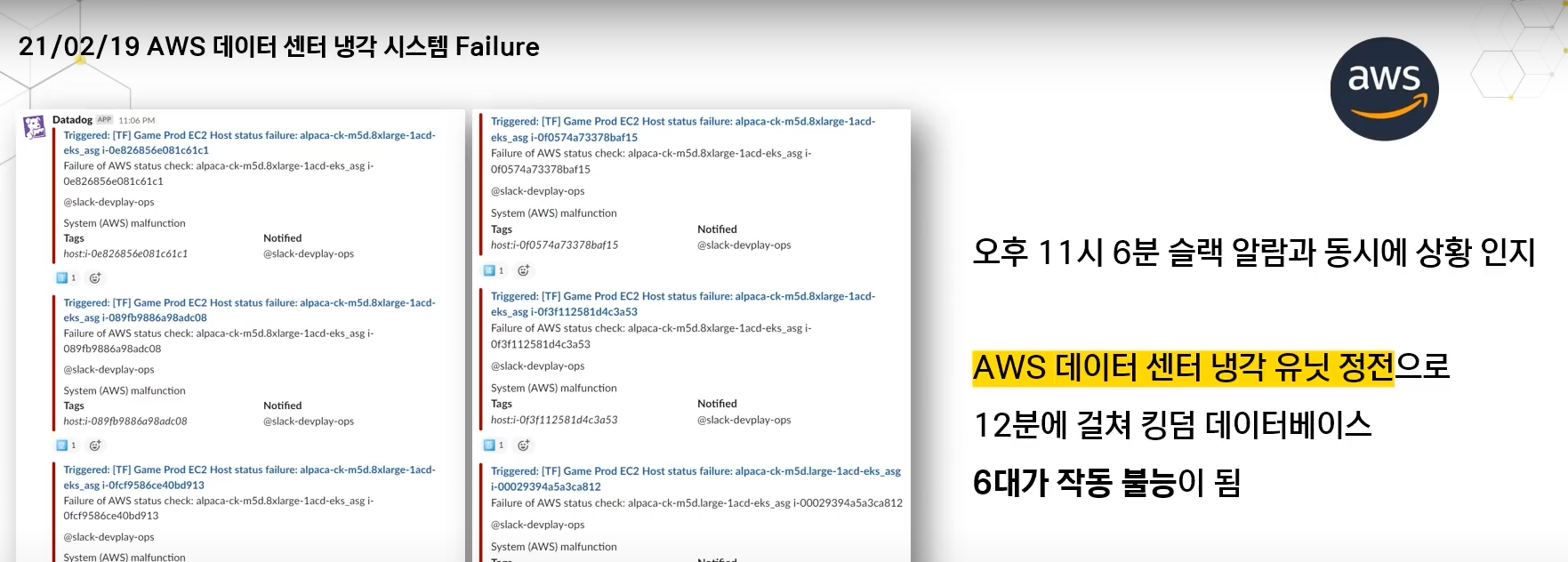
도쿄 리전의 데이터센터 냉각 시스템이 고장나면서 문제 발생

DB 있는 층이 고장

총 34개의 range가 소실
cockroach db를 사용할때 RDB처럼 사용하나 내부로는 key value스토어라 데이터가 바이너리 포맷으로 디스크에 저장되어있음 이 데이터들을 내부에서 적절하게 쪼개는데 이 단위를 range라 함
이 range를 파티셔닝하고 노드간에 복제해서 들고있는 상황 이 range는 replica 복제본을 7개 들고있음
소실된 range들 replica 과반수가 고장난 에어컨 범위에 있던 6대 노드에 있었음
전체 range수는 25000개
32개보다 더 적은 개수가 날아갔을 확률 이 97.7% 이였음
이때 대부분 데이터가 메타데이터성 정보였고 실제 유저 데이터가 들어있던 range는 2개 였음


소실된 range의 살아있는 Leaseholder에서 정보를 읽어서 따로 저장 해놓음
근데 백업이 너무 느렸음

소스 코드를 보다가 위 명령을 발견
공식문서에서도 찾아 볼 수 없고, 살려도 정합성이 맞다는 보장이없음, cockroach labs 엔지니어가 보는 앞에서 사용해라

남은 Range도 첫번째 방식으로 복구는 였음


Locality 설정을 미뤘음 확률이 낮다고 판단해서