
C to C++
C 는 알고있다고 가정했을 때 C++를 얹기 위한 내부 내용들
cpp문법을 아예 모르는 사람은 이해하기 어려운 내용이지만, 문법적인 부분을 한번이라도 알고있다면, C를 깊숙히 이해하고 있는 사람이 Cpp의 내부 작동방식을 이해하기위한 내부 스펙을 서술하는 글
단순한 추가된 단순 문법에 불과하여 검색해서 찾아보고 단순히 받아들이면되는 부분들은 과감히 생략했다. (접근지정자 등)
오버로딩의 원리
인자에 따라서 같은 이름의 함수를 사용할 수 있는데,
이는 사실 컴파일러단에서 함수명을 다르게 만들어버린다.
1
2
3
4
5
6
7
8
9
10
11
12
void func1(int a);
void func1(void* b);
int main()
{
int a = 10;
void *b = 0;
func1(a);
func1(b);
return 0;
}
이렇게 코드를 작성해서 컴파일을 해보자
당연히 링크에러가 발생한다.
1
2
1>소스.obj : error LNK2019: "void __cdecl func1(int)" (?func1@@YAXH@Z)main 함수에서 참조되는 확인할 수 없는 외부 기호
1>소스.obj : error LNK2019: "void __cdecl func1(void *)" (?func1@@YAXPEAX@Z)main 함수에서 참조되는 확인할 수 없는 외부 기호
보면 괴상한 기호가 적혀있는게 실제 링킹단에 참조하는 심볼인데 이는 함수명을 의미한다.
1
2
void __cdecl func1(int) → ?func1@@YAXH@Z
void __cdecl func1(void *) → ?func1@@YAXPEAX@Z
실제로 심볼명을 다르게 하여 다른 함수처럼 취급한다.
Class는 본질적으로 Struct와 같다.
C의 Struct와 Cpp의 Struct 문법 상 차이가 존재하긴 하지만,
C의 Strcut는 Cpp로 거의 그대로 옮겨서 사용할 수 있다. 호환된다.
추가 된거라곤 접근지정자, 메소드, 상속정도 밖에 없다.
이 중 접근지정자는 단순 문법적 제약 정도 밖에 되지않는다.
struct와 class는 디폴트 접근지정자 제외하고는 동일하게 취급된다.
멤버 변수는 결국 C의 struct의 구조체 변수에 불과하다
private 접근 지정자는 멤버 함수 밖에서 쓰지 못하게 추가적인 문법적 제약을 준것에 지니지않는다.
멤버 함수 메소드는 본질적으로 함수다.
python의 멤버함수 정의를 보면 가장 직관적으로 이해할 수 있다.
1
2
instance.method(arg1, arg2, …)
void method (this, arg1, arg2, … )
this를 가장 처음 인자로 던지는게 그냥 생략되어 있다고 생각하면 된다.
조금 더 디테일하게 짚으면 함수 호출 규약에 추가되는 부분이 있는데
콜링컨벤션에서 thiscall 개념이 추가된다.
this 포인터의경우 rcx레지스터(64bit 기준)에 담겨 넘어간다
사실상 일반 함수 call에서 맨 처음 인자가 항상 this가 넘어간다는 것
메소드 내부에서 rcx 레지스터는 그냥 this포인터구나 하면 편하다.
컨스트럭터 디스트럭터
기본함수
- 기본 생성자
- 복사 생성자
- 소멸자
- 대입 연산자
default 함수들의 경우에 컴파일시에 컴파일러단에서 자동 생성하게된다. (cpp 작동방식을 복잡하게 하거나 생각지못한 성능저하를 가져오는 주범이다.)
생성자 소멸자도 결국에 함수다.
생성자
- 지역 객체는 객체가 생성 되는 순간에 생성자 함수를 호출하도록 컴파일 단에서 집어넣는다.
- new를 사용하여 호출하면, 해당 객체에 맞는 생성자 함수를 호출하도록 내부에서 동작한다.
소멸자 :
- 지역 객체가 소별되는 순간( ‘}’ 괄호가 닫히는 순간)에 소멸자 함수를 호출하도록 컴파일단에서 함수를 집어넣는다.
- delete를 사용할시에 해당 객체에 맞는 소멸자 함수를 호출하도록 내부에서 동작한다.
상속
상속은 메모리 구조적으로만 보면 상속받는 멤버변수를 가지는것말고는 크게 차이가 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
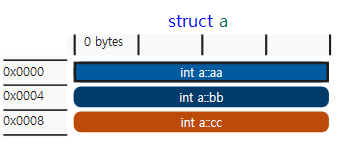
struct a
{
int aa;
int bb;
int cc;
};
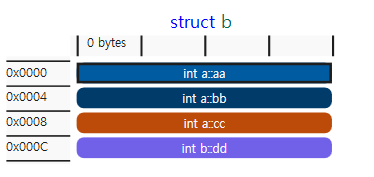
struct b : public a
{
int dd;
};
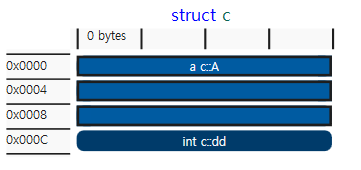
struct c
{
a A;
int dd;
};
static_assert(sizeof(b) == sizeof(c));
구조체 b와 c의 메모리 구조는 동일하다.
물론 상속을 받아야만 객체가 직접 a의 함수를 사용하고, 가상함수를 구현 할 수 있다.
가상함수(오버라이딩)의 원리
가상함수라는 신기한 방식은 함수 포인터의 테이블을 만들고 접근함으로써 트릭을 구현한다.
- virtual 함수가 있는 객체는 this 포인터 자리에 8바이트 테이블을 추가로 가지게된다. 멤버변수가 없더라도 해당 객체는 size 8을 가지게된다. (멤버변수가 없을경우 기존 클래스 객체는 1byte를 가진다.) 구현 코드에서 해당 테이블의 존재 유무를 놓칠수있어 객체의 사이즈 계산 등에서 유의해야한다.
- 컴파일시에 함수 주소가 고정적으로 박혀 고정 call을 하는것이 아닌 테이블의 함수 주소를 call한다 . 가상함수 호출은 해당 테이블의 함수포인터 접근을 함으로 호출한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class A {
public:
void func1() {}
virtual void func2() {}
};
class B : public A
{
public:
virtual void func2() override {}
};
static_assert(sizeof(A) == 8, "");
int main()
{
B aa;
A *a = &aa;
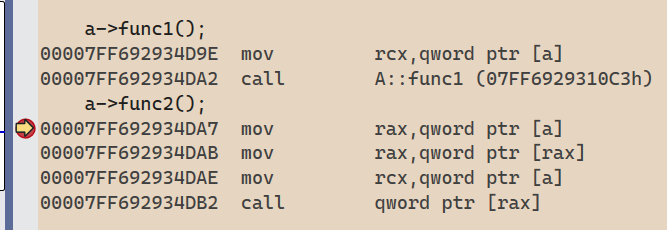
a->func1();
a->func2();
return 0;
}
해당 코드를 instruction으로 보면 아래와 같다.
Cpp의 코드를 virtual table을 활용한 C 코드로 나타내면 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
#include <stdio.h>
struct A;
typedef struct {
void (*A)(struct A*);
void (*update)(struct A*);
int (*access)(struct A*);
void (*A)(struct A*);
} A_virtual_table;
typedef struct A {
A_virtual_table* vmt;
int a;
} A;
void A_Constructor(A* this);
void A_Destructor(A* this);
void A_update(A* this);
int A_access(A* this);
A_virtual_table A_vmt = { A_Constructor, A_update, A_access, A_Destructor };
void A_Constructor(A* this) { this->vmt = &A_vmt; this->a = 10; }
void A_update(A* this) { this->a++; }
int A_access(A* this) { this->vmt->update(this); return this->a; }
void A_Destructor(A* this) { ; }
struct B;
typedef struct {
void (*B)(struct B*);
void (*update)(struct B*);
int (*access)(struct A*);
void (*B)(struct B*);
} B_virtual_table;
typedef struct B {
A inherited;
} B;
void B_Constructor(B* this);
void B_update(B* this);
void B_Destructor(B* this);
B_virtual_table B_vmt = { B_Constructor, B_update, A_access, B_Destructor };
void B_Constructor(B* this) { A_Constructor(this); this->inherited.vmt = &B_vmt; }
void B_update(B* this) { this->inherited.a--; }
int B_access(B* this) { this->inherited.vmt->update(this); return this->inherited.a; }
void B_Destructor(B* this) {}
int main() {
A x;
B y;
A_Constructor(&x);
B_Constructor(&y);
printf("%d\n", x.vmt->access(&x));
printf("%d\n", y.inherited.vmt->access(&y));
B_Destructor(&y);
A_Destructor(&x);
}
람다 함수
이름 없는 함수
진짜 이름이 없는 함수다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void fun1() {
return;
}
int main()
{
fun1();
auto fun = [] () {
return 1;
};
int b = fun();
return 0;
}
이런함수를 한번 만들어보자.
visual studio의 내부 툴중에 dumpbin이라는 툴이 존재한다.
obj, exe파일들의 실제 내부 구조를 볼 수 있는 지원툴이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
02B 00000000 SECT8 notype () External | ?fun1@@YAXXZ (void __cdecl fun1(void))
02C 00000000 SECTC notype () External | main
02D 00000000 SECT4 notype () Static | ??R<lambda_1>@?1??main@@YAHXZ@QEBA@XZ (public: __cdecl `int __cdecl main(void)'::`2'::<lambda_1>::operator()(void)const )
02E 00000000 SECT6 notype () Static | ??R<lambda_2>@?1??main@@YAHXZ@QEBA@XZ (public: __cdecl `int __cdecl main(void)'::`2'::<lambda_2>::operator()(void)const )
02F 00000000 UNDEF notype () External | _RTC_CheckStackVars
030 00000000 UNDEF notype () External | _RTC_InitBase
031 00000000 UNDEF notype () External | _RTC_Shutdown
032 00000000 UNDEF notype () External | __CheckForDebuggerJustMyCode
033 00000000 UNDEF notype () External | __GSHandlerCheck
034 00000000 SECTA notype () External | __JustMyCode_Default
035 00000000 UNDEF notype () External | __security_check_cookie
036 00000000 SECT8 notype Label | $LN3
037 00000000 SECTC notype Label | $LN3
038 00000000 SECTE notype Static | .xdata
R
덤프파일, 심볼을 가지고 함수를 추적하는데 어려움이 많아진다.
Template의 원리
템플릿 코드는 실제 코드가 아니다.
매크로 define과 비슷한 방식인데, define이 호출될때 컴파일에서 해당 코드에다가 직접 찍어내는 것처럼 template 코드 자체로서는 실제 컴파일 코드에 영향을 미치지않고, 실제 사용부가 존재하게 될때, 코드가 생성된다.
코드 단에서
1
2
3
4
5
#include <vector>
int main(){
return 0;
}
이런 식으로 할때는 vector 클래스는 구현되지않는다. (컴파일 시에 코드단에 존재하지않음)
1
2
3
4
5
6
#include <vector>
int main(){
std::vector<int> a;
return 0;
}
최적화등으로 삭제되는 경우를 제외하고 그냥 코드 그대로만 봤을때 이렇게 호출하는 부분이 있으면 vector
그래서 구현부 분리를 할 수 없는 구조로 되어있다.
왜 헤더파일과 cpp로 분리할 수 없는가에 대한 대답이 된다.
이는 파일별로 생성되며, linux기준 링킹단에서 중복되는 약한 심볼로서 적당한 한놈을 골라 그걸로 묶어버린다.
7개의 cpp파일에서 std::vector
큰 프로젝트 일수록 과하게 사용할 경우 주요 프로젝트 컴파일이 오래걸리게되는 원인이 될 수 있다.
이 정도 이해했으면 나머지 Cpp의 문법은 컴파일에서 잡는 일반 언어 문법이구나 정도로 받아들이면 된다.
예를 들어 접근지정자의 경우 C에는 없는 개념인데 private이라는 개념을 집어넣어서 외부에서 사용할시에 컴파일러가 외부에서 사용했군이라고 문법 체크에서 잡아내는것.
C 계열 언어들로만 봤을때 내부 구조는 비슷하고 문법적인 생김새만 조금씩 다르고 얼마나 사용자 친화적인지, 실수를 방지하는지 이에 대해서 문법적인 지원, 제한의 차이가 있을 뿐이다.
학생 시절 C 만 굉장히 오래 써 왔고 C++, C# 을 주로 다루는 현시점에서 OOP가 어떠니 절차지향이 어떠니 하는패러다임 같은 얘기들의 논의를 봤을때 봐도 잘 공감을 못 하게되었다.
결국 어셈ㅡ기계어단에서는 언어 패러다임과 관계없이 모두 절차적으로 수행되고 cpu의 pc레지스터는 함수 주소따라 메모리상을 뛰어다닐 뿐이다.
물론 코어가 여러개, 스레드가 분리되면 각각 개별적인 얘기인지라, 하나의 컨텍스트 상에서로 한정했을때 얘기.