
object pool 만들기
obejct pool을 직접 만들어보면서 발전 과정과 고려사항을 정리한 글입니다.
해당 메모리 풀에서 시작했으나 멀티스레드 환경에서 이 pool을 어떻게 발전 시킬 수 있을까 고민한 과정이다. 이 object pool 정책 방식은 그대로 고정메모리 memory pool로서도 사용할 수 있다.
기본 아이디어
- 여러개를 할당하여 들고있는데
- 주고 받는데 락을 걸어서 재사용한다.
여기서 1차적인 가장 기본적인 objectpool은 완성되었다.
요걸 구현상 상세 고려점을 정리해본다.
- pool에서 메모리가 부족할경우 추가되는 경우까지 고려.
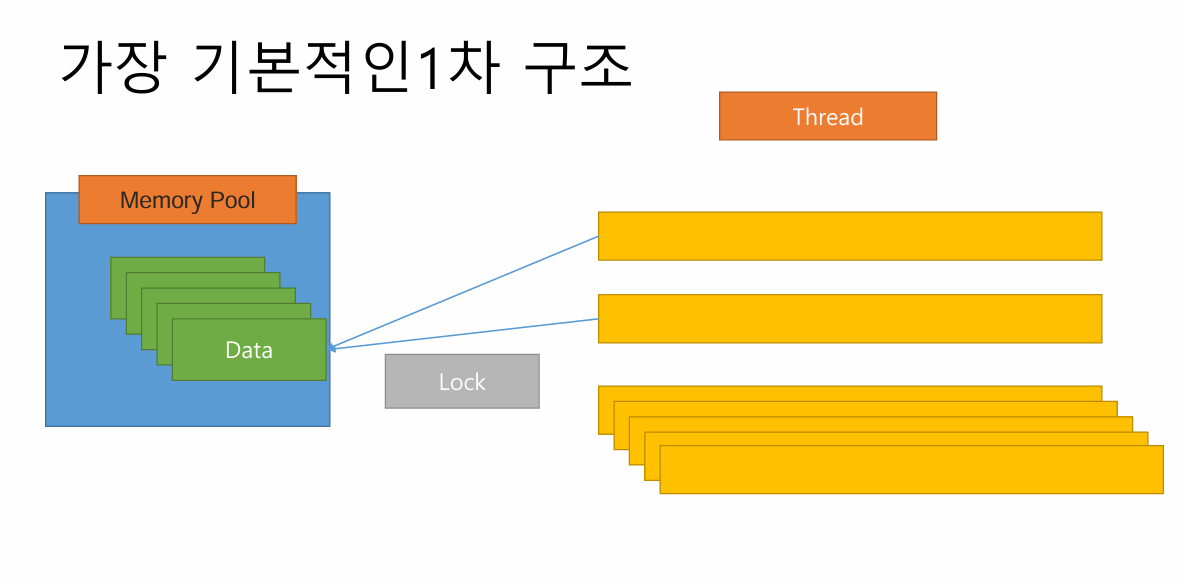
가장 기본적인건 단일 락으로 들고있는거다. 이렇게 했을때 경합이 클때 Lock 부하가 생긴다.
pool에서 들고 있을 자료구조 정책
- list
- array 기반(vector)
- CAS 기반 Lock-Free 자료구조
list
std::list는 list넣고 빼는데에 내부에서 node할당 해제가 발생한다. (정확하게 어떻게되나 보려고 std::list 코드도 뜯어봤다;) 직접 node를 할당해제하는 object pool을 만들어서 할 수도있는데 생각하면 생각할수록 구조가 복잡해져서 탈락
array 기반(vector)
- vector
: 빈 객체들 별도 관리 자료구조 필요, 확장 불가, 사용 불가 - vector<T*> : 포인터 관리, 확장 가능, 사용 가능,
- -> 그러나 vector 확장시 메모리 비용 발생
CAS 기반 Lock-Free 자료구조
lock free 자료구조를 안좋아하는 편이라 가능하면 피하고 싶다.
- Lock Free 자체 구현 난이도가 너무 높다.
- 그리고 성능 또한 제대로 만들어졌다고 보장하기 어렵다.
- 대부분의 블로그들에 널려있는 Lock Free 코드들은 실제 spinlock 구현에서 사용하는 pause 명령어가 빠져있어 실제 데이터 경합 발생시 SRWLock 보다 성능이 안나올게 뻔하다.
- 이걸 고려하고 구현하고 만드려면 실제 사용되는 spinlock, lock free 코드를 어셈단위로 분석해서 돌아가는것을 분석해서 구현해야하는데
- 이후 시스템이 발전함에 있어서까지 작업자가 고려하여, 파악하고 유지보수하는것을 불가능하다고 생각한다.
결정적으로 이후 TLS 기반으로 하여 데이터 경합자체를 최소한으로 하는것을 목표로할거기에 이 경우에 CAS까지 고려하면서 쥐어짤 필요가 없다고 생각하여 CAS는 고려하지않는다.
CAS 자체를 해당 obejct pool 구현하는데 쓸 필요는 없을 것 같다.
Two-Lock Queue 같은 구조 또한 고려했었으나, 캐시 효율성을 생각했을때, Queue 구조보다는 Stack 구조가 훨씬 낫다고 생각하여 탈락.
spin-lock 구현과 관련한 다양한 이슈는 이후에 별도 포스팅으로 다룰 예정이다.
자료구조 최종 선택
일반적으로 vector를 고르겠지만 자체 List를 구현하는것으로 결정했다. 실제 단순 object pool 구현 난이도는 vector가 훨씬 간단하나..
List를 고른 이유는 다음과 같다.
vector를 하더라도 구조적으로 결국에 객체별 메모리 할당이 필요하고, T*배열이라 배열에 대한 메모리 할당도 필요하면, 차라리 node의 메모리할당을 객체까지 포함하여 한번만 해버리는게 구조적으로 더 간단해진다.
1안 node 구조
1
2
3
4
5
6
//1안
struct node
{
node* next;
T data;
};
pool에서 반환할때는 data 주소만 반환하고, 받을때는 data주소에서 node주소를 구해서 next에 연결하는 방식이다. (이때 next 포인터는 캐시를 고려해 data아래보다는 위로 잡았다.)
이렇게 했을떄 한가지 발생하는 문제점은, pool에 들어가는 객체는 무조건 pool에서 받아온 객체여야하는게 보장되어야한다. 그게 아니면 바로 heap을 긁어버린다.
2안 node 구조
pool에 있는 객체들은 결국에 빈 메모리 깡통들이기에 node 포인터에 할당 되는 메모리 또한 아끼고 싶을때, 아래 처럼 객체 메모리 공간을 직접 Node *로 쓰는 방법도 있다.
이 경우 위와 같이 pool에 들어가는 객체가 그냥 외부에서 new로 할당한 객체가 들어가도 아무 문제가 없다.
1
2
3
4
5
//2안
union Node {
Node* next;
T data;
};
node 구조는 처음엔 2안으로 작업을 진행했었다가, 이후 TLS 작업을 하면서 객체 풀에 들어가는 객체가 단순한 메모리 덩어리들인 가정이 깨지면서 다시 1안으로 돌아갔다;
기본 락은 SRWLock으로 구현하였다.
여기까지 Object Pool의 기본적인 형태와 고려사항을 정리했다.
추가 구현시 참고사항 : pool이 비어있을때 정책
기본적으로 pool에 빈객체가 없을때 추가 할당을 받아야하는데,
최우선 고려사항은 이때 lock을 잡고 작업하지않도록 고려해야한다.
- lock을 잡고 메모리 할당을 진행하는 순간 lock 경합 비용이 매우 올라간다.
- lock잡는건 자료구조를 직접 건들때만하고 그 외에는 lock을 잡지않도록 구현해야한다.
- 따라서 이때 구현시에 Lock을 잡지않고 객체를 할당받고 pool에 추가하는 작업을 해야한다.
- 물론 이렇게 했을때 동시 다발적으로 접근하는 스레드 전체적으로 각자 객체를 할당하고(여기서 결국 malloc 경합이 발생할 수도..) pool에 추가하는 작업이 발생할 수 있다.
추가 고려사항
- 적당히 pool 갯수가 몇개 이하일때 미리 몇개씩 만들어서 pool에 집어넣는 관리 스레드(or async 작업)가 별도로 있는것도 고려해 볼 법하다고 생각한다.
- 이게 잘 굴러가면 이제 객체를 가져가는 pool에서는 객체를 생성해야하는 비용을 없앨 수 있을 것이다.
TLS 정책
TLS 기반 메모리풀의 문제
스레드 별 메모리 풀이라고 했을때, 처음 생각한건 정말로 스레드 별로 메모리 풀로서 lock을 잡지않는것을 생각하고 해당 방향으로 구상을 했었다. Windows의 PrivateHeap을 사용해서 Heap할당시 메모리 할당을 하지않는 방향으로도 생각해봤는데 다른 스레드에서 해제를 할경우 문제가 발생한다.
구현상 요구 사항은
- 스레드 A에서 할당한 객체를 스레드 B에서 해제할 수 있어야한다.
이 경우 TLS 캐시에 객체가 없을때만. 메모리 풀에서 객체를 가져오도록 한다.
TLS 캐시 고려사항
이를 위해 TLS에서 들고 있을 객체 풀이 존재해야한다. 이 객체 풀을 global 객체풀에서 가져올때 lock비용을 최소화 해야한다.
즉 global 객체풀은 객체풀의 객체풀이 되어야한다.
- 따라서 아래와 같은 구조가 된다.
TLS 객체 풀을 위한 struct Segment를 추가로 만들었다.
이 객체들을 들고잇는 객체는 vector로 하였다. (고정배열도 가능)
따라서 전역 객체풀은 ObejctPool<Segment
이 Segment상에서 객체를 넣고 뺄때는 lock 을 걸지 않아도 된다.
이렇게 했을때 빈 Segment의 메모리 관리가 추가적으로 필요하다.
따라서 ObjectPool이 두개가 필요해졌다.
- FilledSegmentPool : 꽉찬 Segment를 관리하는 ObjectPool
- EmptySegmentPool : 비어있는 Segment를 관리하는 ObjectPool
- Segement 배열이 꽉찼을때, FilledSegmentPool로 밀어넣고, EmptySegmentPool에서 꺼내온다
- Segment 배열이 비었을때, EmptySegmentPool로 밀어넣고, FilledSegmentPool에서 꺼내온다.
각 Sement의 초기 상태를 어떻게 꽉찬것과 빈것으로 만들까 고민을 했을때 별도 struct FilledSegment를 구현하였다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename T>
struct FullSegment : public Segment<T>
{
FullSegment()
{
for (T*& item : Segment<T>::m_Objects)
{
item = new T();
}
}
};
static_assert(sizeof(FullSegment<int>) == sizeof(Segment<int>), "FullSegment and Segment must have the same size.");
static CObjectPool<FullSegment<T>> GLOBAL_FILLED_SEGMENT_POOL;
이렇게 하면 Segment와 FullSegment의 크기가 동일하므로 서로 간엔 pointer캐스팅만해서 그냥 동일하게 쓰는것으로 했다.
추가 고려사항 : 최악의 케이스 Global pool과 TLS pool간의 경계선상에서의 문제
위와 같은 구조로 했을떄, 최악의 발생 케이스로 아래가 발생할 수 있다
- Full이 된 상황에서 GlobalFilledSegmentPool에 밀어넣고, GlobalEmptySegmentPool에서 받아옴
- 코드단에서 연속으로 할당을 받아가 현재 Segment가 모자라게되어, GlobalEmptySegmentPool에 밀어넣고 다시 FilledSegmentPool에서 할당
- 반복
케이스 따라서 경계 선상에서 계속 글로벌로 접근하는 케이스가 발생할 수 잇으니, Global pool에 바로 넣지않고 별도 로컬 Filled Segment, Empty Segment 포인터를 TLS에 추가로 들고있도록 하였다. Global pool에 넣는 케이스는 각 케이스가 두 번 생겼을때 하나를 집어넣도록 하였다.

반환케이스 : Segment가 가득 찼을때

요구케이스 : Segment가 비어서 필요할때
추가 고려사항
Segment를 배열이아닌 리스트로 해도 가능은 하지않을까 싶다. 2차 리스트구조로 가면 메모리 구조가 너무 복잡해져서 고려하진않았으나..
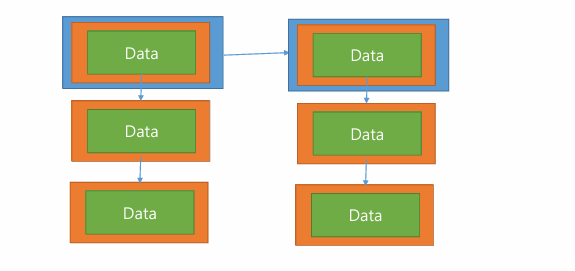
vector 배열 메모리를 신경쓸필요가 없어지는것이 확실히 장점이 된다.
구조 자체는 더 단순해졌을것같다.