
Sleep Loop로 전력과 성능 개선하기
원문: https://www.isus.jp/hpc/benefitting-sleep-loops/ (iSUS 일본어 참고역, Intel 원문: https://software.intel.com/en-us/articles/benefitting-power-and-performance-sleep-loops)
문제의 개요
최신 멀티코어 프로세서를 최대한 활용하기 위해, 개발자는 작업을 다루기 쉬운 크기로 분할하고 스레드 풀을 사용해 동시에 실행되는 여러 스레드에 분배하는 방법이 일반적이 되었습니다. 스레드 풀의 성능과 전력 소비 문제는 보통 여러 스레드가 작업을 요청해 작업 큐에서 높은 경합이 발생하는 경우나, 여러 스레드가 큐에서 작업을 대기하고 있는 경우에 발생합니다. 이 문제를 해결하는 알고리즘은 여러 가지가 있지만, 여기서는 가장 자주 사용되며 구현 전체를 재설계하지 않고도 간단한 변경으로 성능과 전력 소비를 향상시킬 수 있는 알고리즘을 설명합니다.
이 문제를 해결하기 위해 흔히 사용되는 방법은, 스레드 풀 내의 각 스레드가 큐의 작업을 항상 확인하고, 작업이 발생하면 즉시 처리하기 시작하는 것입니다. 이는 매우 단순한 방법이지만, 개발자는 종종 큐에서 작업을 폴링하는 방식이나 큐에서 높은 경합이 발생했을 때의 대처 방법에서 문제에 직면합니다. 다음 두 가지 상황에서 문제가 발생합니다.
- 작업 큐에 충분한 작업이 없어 워커 스레드가 작업을 기다리고 있는 경우.
- 동시에 큐에서 작업을 가져오려는 스레드가 많아 큐를 보호하는 락에서 경합 상태가 발생하고, 이를 완화하기 위해 스레드가 락 획득을 포기해야 하는 경우. 이 글은 흔히 사용되는 스레드 풀 구현의 함정과, 간단한 변경으로 소비 전력과 성능을 크게 향상시키는 방법을 설명합니다.
여기서는 이해를 돕기 위해, 균등하고 독립적으로 분할 가능한 큰 데이터셋을 워크로드로 가정합니다.
sleep loop의 알고리즘 상세
여기서 사용하는 예에서는, 각 스레드가 작업 큐에 접근하려 하기 때문에, 정해진 수의 스레드만이 동시에 작업을 가져올 수 있도록 락을 사용해 큐 접근을 보호할 필요가 있습니다.
이를 고려한 단일 스레드 알고리즘의 흐름은 다음과 같습니다.
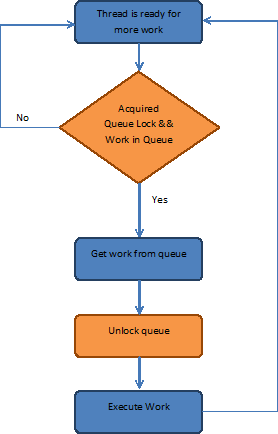
Windows 플랫폼에서 이 알고리즘의 문제점
스레드 풀이 어디서 작동하지 않게 되는지는 구현 방식에 달려 있지만, 여기서 중요한 것은 큐에 작업이 없거나 스레드가 큐에 대한 락 획득에 실패했을 때 어떻게 대처하느냐입니다. 가장 단순한 대처 방법은 계속 확인하는 것으로, 이는 “busy wait” 루프라고 부릅니다. 아래에 의사 코드를 보입니다.
1
2
3
4
while (!acquire_lock() && work_in_queue);
get_work();
release_lock();
do_work();
표 1: busy wait 루프
이 구현의 문제는 스레드가 락을 획득할 수 없거나 큐에 작업이 없을 때 스레드가 곧바로 확인을 계속한다는 점입니다. 잦은 폴링은 사용 가능한 모든 프로세서 리소스를 소모하며, 성능과 전력 소비 모두에 영향을 줍니다. 다만 좋은 점도 있어, 락이나 작업이 사용 가능해지면 스레드는 즉시 큐에 들어갈 수 있습니다.
큐나 높은 경합 상태에 있는 락의 확인을 멈추기 위해 Win32 API의 Sleep(0)을 호출합니다. MSDN 문서에 따르면 Sleep(0)을 호출하면 호출자 스레드보다 높은 우선순위를 가진 스레드가 실행 가능할 때만 호출자 스레드가 남은 타임 슬라이스를 포기합니다. 즉, 스레드는 항상 확인하는 대신, 다른 유효한 작업이 보류되어 있지 않은 경우에만 확인합니다. 더 적극적인 방법이 필요하면, 항상 남은 타임 슬라이스를 포기하는 Sleep(1)을 호출해 스위치 아웃합니다. Sleep(1)을 사용하면 스레드는 1밀리초 후에 웨이크업하여 확인을 재개합니다.
1
2
3
4
5
6
7
while (!acquire_lock() || no_work_in_queue)
{
Sleep(0);
}
get_work();
release_lock();
do_work();
표 2: sleep loop
이 밖에도 OS 내부에서는 성능을 크게 저하시킬 수 있는 여러 가지 일이 일어납니다. Sleep(0) 호출은 명령 경로가 상당히 길고, 약 1,000사이클을 소모하는 링3에서 링0으로의 전환이 있어 오버헤드가 발생합니다. 프로세서는 이 “sleep loop”가 유효한 작업을 수행하고 있다고 믿습니다. 이러한 명령을 실행함으로써 프로세서는 최대한 활용되어 파이프라인에 명령을 보내고 실행하며 캐시를 폐기합니다. 여기서 주의할 점은 프로그램에 도움이 되지 않는 것에 전력이 소비되고 있다는 점입니다.
더 나아가, Sleep(1) 호출은 Windows 커널의 클록 틱이 기본 15.6밀리초인 경우 개발자의 의도대로 동작하지 않을 가능성이 큽니다. 기본 클록 틱에서는 이 호출이 1밀리초보다 훨씬 긴 수면과 같아서, 커널이 웨이크할 때까지 스레드는 웨이크하지 않으므로 15.6밀리초나 대기하게 됩니다. 즉, 이러한 호출에서는 락이 사용 가능해지거나 작업이 큐에 추가되어도 스레드가 즉시 활성화되지 않습니다.
또 다른 문제로, 곧바로 남은 타임 슬라이스를 포기함으로써 실행 스레드가 스위치 아웃됩니다. 컨텍스트 스위치는 약 5,000사이클이 걸리므로, 스위치 아웃하고 스위치 백하는 데 최소 10,000사이클의 오버헤드가 발생해 그만큼 워크로드 완료가 늦어집니다. 대부분의 경우 이러한 루프는 빈번한 컨텍스트 스위치를 발생시킵니다. 이는 오버헤드가 존재하며 성능 향상의 여지가 있음을 시사합니다.
다행히도, 이 오버헤드를 제거하고 소비 전력을 억제하며 성능을 향상시킬 수 있는 대안이 있습니다.
해결 방법
여기서 권장하는 대안은 보다 단계적인 백오프라고 할 수 있는 알고리즘입니다. 처음에는 스레드에 짧게 락을 스핀시키지만, 완전히 스핀하는 대신 루프에 pause 명령을 추가합니다. 인텔 SSE2 명령어 세트에 추가된 pause 명령은 프로세서에 호출자 스레드가 “spin-wait” 루프 내에 있음을 알립니다.
이 pause 명령은 SSE2에 대응하지 않는 x86 아키텍처에서는 no-op이 되어 아무 처리를 하지 않는 명령이 실행되거나 폴트가 발생합니다. 즉, SSE2에 대응하지 않는 오래된 x86 아키텍처에서는 pause 명령을 사용할 수 없지만, 개발자는 전체적으로 하나의 단순한 코드 경로를 유지할 수 있습니다.
기본적으로 이 명령은 다음 명령의 실행을 일정 시간 지연합니다. 다음 명령의 실행을 지연함으로써 프로세서에 요구가 보내지지 않고 파이프라인의 일부가 미사용 상태가 되어 프로세서의 소비 전력을 줄일 수 있습니다. 짧은 시간에 락이나 작업이 사용 가능해지는 상황에서, pause와 Sleep(0)을 혼용하면 지수 백오프처럼 동작하며, 링3의 스핀이 짧아짐으로써 성능 향상이 기대됩니다. 아래에 이 알고리즘을 보입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
ATTEMPT_AGAIN:
if (!acquire_lock())
{
/* 수면에 들어가기 전에 pause를 max_spin_count 번 스핀 */
for(int j = 0; j < max_spin_count; ++j)
{
/* pause 내장 명령 */
_mm_pause();
if (read_volatile_lock())
{
if (acquire_lock())
{
goto PROTECTED_CODE;
}
}
}
/* 루프에서 pause에 실패, 수면으로 진입 */
Sleep(0);
goto ATTEMPT_AGAIN;
}
PROTECTED_CODE:
get_work();
release_lock();
do_work();
표 3: 급격한 탈출 메커니즘을 가진 sleep loop
실제 프로그램에서의 pause 사용
pause 명령을 포함한 표 3의 알고리즘을 사용함으로써 소비 전력과 성능 모두가 크게 향상됩니다. 테스트에서는 3개의 워크로드를 사용했고, 각각에서 시간이 많이 드는 능동적인 작업을 수행했습니다. 입자(작업) 크기가 거칠면 작업이 비교적 광범위하여 스레드가 락 경합을 일으키는 일이 거의 없습니다. 입자 크기가 세밀하면 작업이 짧아 스레드는 더 많은 태스크를 종료하고 다음 태스크에 사용 가능해집니다.
다음 측정 결과는 6코어, 12스레드의 인텔® Core™ i7 990X와 동등한 시스템에서 측정되었습니다. 성능 향상은 놀라웠습니다. Sleep(0)만 사용해도, 8스레드에서는 최대 4배, 32스레드에서도 약 3배의 성능 향상이 있었습니다.

표 4: pause를 사용한 경우의 성능

표 5: pause를 사용한 경우의 성능
앞서 말했듯, pause 명령을 사용하면 스레드가 대기 중일 때 프로세서 파이프라인 사용을 억제해 소비 전력을 줄일 수 있습니다. 계측기를 사용해 두 알고리즘의 소비 전력 차이를 측정해 보았습니다.
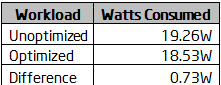
표 6: 최적화 유무에 따른 소비 전력
표준 구현보다 약 0.73W 정도 더 절전임을 알 수 있습니다. 즉, 이러한 프로그램은 랩톱 배터리 소모의 원인이 되기 어렵습니다. 적극적인 절전과 성능 향상은 워크로드 전체의 소비 전력을 크게 줄입니다.
정리
여기서 소개한 알고리즘처럼, 많은 경우에 개발자가 간과하거나 단지 깨닫지 못한 수많은 성능 관련 문제가 숨어 있습니다. 우리는 수년에 걸친 조사와 측정을 통해 이러한 문제를 해결할 수 있었습니다.
여러분이 여기서 소개한 솔루션을 기존 소프트웨어에 쉽게 도입할 수 있기를 바랍니다. 이 솔루션은 일반적인 알고리즘을 사용하면서도 큰 영향을 주는 변경을 조금 가한 것입니다. 휴대 기기가 널리 보급되고 배터리 수명이 더욱 중요해지는 가운데, 개발자는 다양한 점을 고려하여 새로운 명령을 활용하고 성능과 소비 전력을 모두 향상시킬 수 있습니다.
저자 소개
Joe Olivas는 인텔의 소프트웨어 엔지니어로, 다른 소프트웨어 벤더를 위해 소프트웨어 성능 최적화를 수행하고 새로운 분석 도구 개발에도 참여하고 있습니다. 캘리포니아 주립대 새크라멘토에서 컴퓨터 과학 학사와 석사를 취득했습니다(전공은 암호 프리미티브와 성능). 소프트웨어 최적화에 매진하지 않을 때는 집을 리모델링하거나 부인과 함께 홈브루 맥주를 양조합니다.
Mike Chynoweth는 인텔의 소프트웨어 엔지니어로, 소프트웨어 성능 최적화와 분석에 종사하고 있습니다. 플로리다 대학교에서 화학공학 학사를 취득했습니다. 새로운 성능 분석 기법에 매진하지 않을 때는 디주리두 연주, 사이클링, 하이킹 등을 즐기거나 가족과 시간을 보냅니다.