
멀티스레딩 환경에서의 shared_ptr
- 이전글 shared_ptr 구현 분석
대부분의 cpp에서 modern cpp로 넘어갈때 shared_ptr은 기초적인 내용정도는 전부 학습하게 된다. STL은 당연하겠지만, standard로 제공해주는 표준이다보니, 많은 경우에 사용자 입장에서 어련히 잘 만들었겠거니 하고 사용하게 된다.
당연히 STL 종류에 따라서 이것이 thread_safe 한가는 항상 따지는 부분이나, 특히 shared_ptr의 경우에는 ref count를 atomic하게 다루는 것 또한 기본적으로 알고 있기에, thread_safe하다고 생각하기 쉬운 부분이 있어, 멀티스레딩 환경에서의 shared_ptr과 조금 더 복잡한 스펙에 대해서 정리해보고자 한다.
사실 내가 thread_safe하다고 생각한 것이고, 별도 의문을 품은 적 또한 없었고, 구현 코드마저 본적이 있지만, 지금껏 이런 이슈에 대해 생각해 본적이 없었다. 최근에 이런 이슈가 발생할 수 있음을 인지하고 조금 더 자세히 알아보게 되었다.
포인터가 가르키는 객체는 thread-safe하지 않다.
지금의 내 입장에선 너무 당연하지만.. 회사를 다니기 전에는 멀티스레드 환경에서 코드를 shared_ptr같이 smart pointer를 사용해서 코드를 작성해볼 일이 없었던지라 관련해서 고민해본적이 없었고, 처음 신입 면접에서 이 질문을 받았을때, 메모리 관리를 atomic하게 관리하기에 shared_ptr이 thread safe하다고 생각했고, 그렇다고 답변을 해버렸다..
당연하지만 락을 걸어야한다.
ref counting에서 atomic연산 또한 데이터 경합이 생기면, 성능이 떨어진다.
나중에 별도로 다룰일이 있겠지만, interlock도 결국에는 해당 메모리 변수 값이 변경되면, 다른 스레드에선 메모리에 새로 로드해야하기에, 스레드 경합이 심할수록 성능이 떨어진다.
enable_shared_from_this
enable_shared_from_this는 CRTP (Curiously Recurring Template Pattern) 패턴을 이용해서 shared_ptr이 가르키는 객체가 자기 자신에 대한 shared_ptr을 생성할 수 있도록 하는 클래스이다.
shared_ptr 또한 결국 thread safe 하지않다.
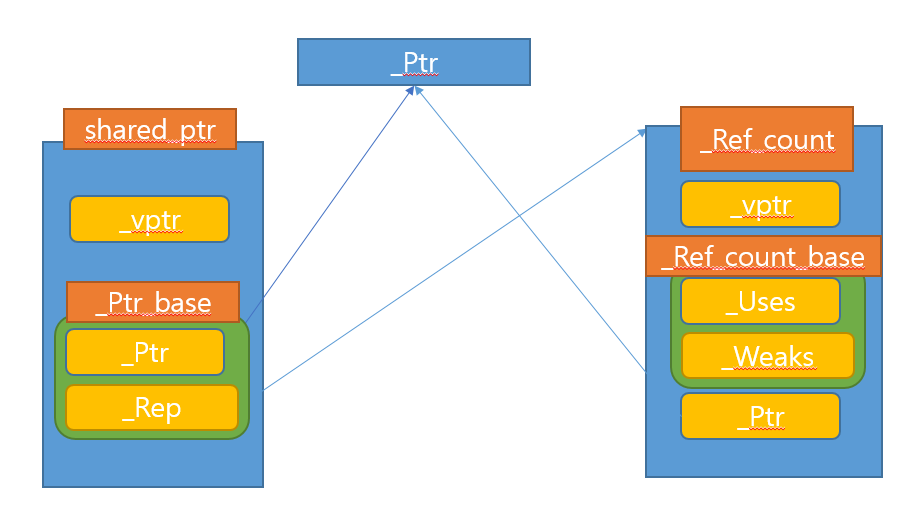
pointer 대입을 생각해보자, 여기 shared_ptr 객체가 가르키는 포인터 변수는 두개이다. 따라서 이 모든 변수의 thread_safe함이 보장되려면, _Ptr, _Rep 이 두 포인터가 같이 변경됨이 보장되어야하고, 별도 락 변수를 두고 락을 잡든, interlock으로 쇼를 하든 처리해야한다.
shared_ptr은 거기까지 처리하진 않는다. 따라서 데이터에 race condition이 발생한다.
이를 위한 보완책으로 [std::atomic
구현을 잠깐 봤을때는 template specialization으로 atomic하게 처리하는 방식이었고, loop 기반 spin lock으로 구현되어있다. (장시간 __std_atomic_wait_direct 대기는 Windows에서는 WaitOnAddress를 호출한다.)
make_shared
make_shared는 shared_ptr을 생성하는데 있어서, 객체와 ref count를 하나의 메모리 블록에 할당하여 메모리 할당 횟수와 단편화를 줄인다.
방식은 이렇다
- _Rep 객체의 실 포인터는_Ref_count_base 포인터인데 각각 케이스에 따라서 생성하는 객체가 다르다.
기본할당
1
std::shared_ptr<int> ptr1 = std::shared_ptr<int>(new int(42));
- _Rep 객체 타입 _Ref_count, 위 사진과 같은 케이스로 new 두번 발생.
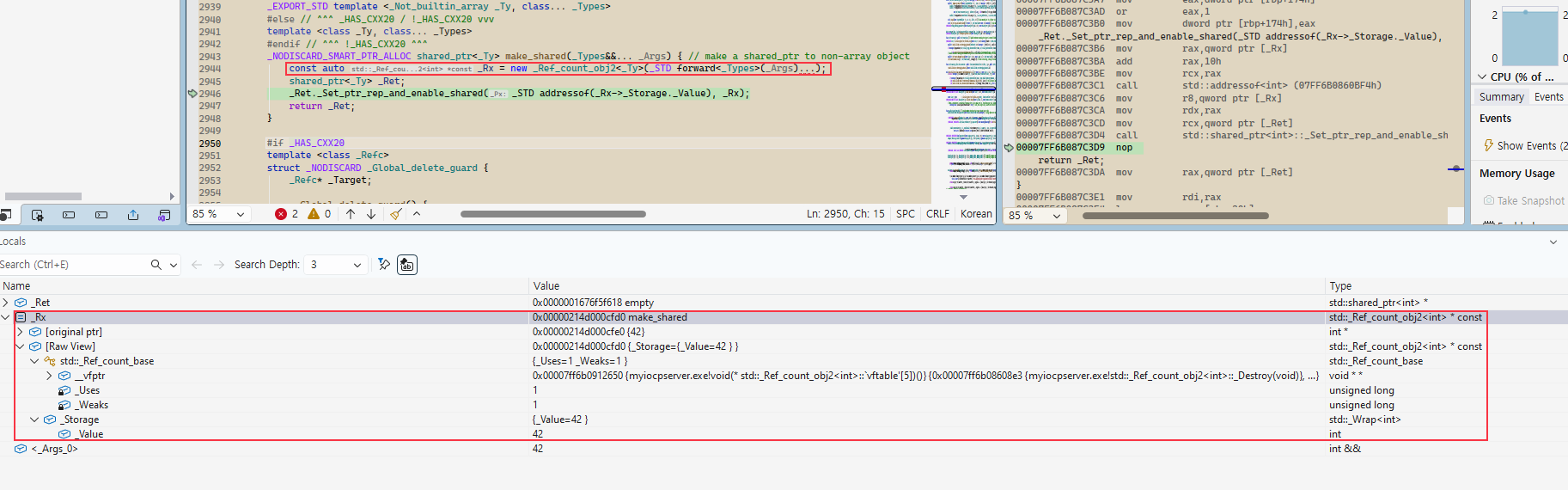
1
std::shared_ptr<int> ptr2 = std::make_shared<int>(42);
- _Rep 객체 타입 _Ref_count_obj2, new 한번 발생
delete시에도 각 객체의 상속받은 함수의 구현부에 따라 delete를 맞춰한다.
음… 이런걸 알아 볼 때마다 드는 생각이 있다.
복잡한 STL 내부 구현 및 유의 사항까지 파악해야 비로소 제대로 쓸 수 있는데, 함수 뎊스도 깊고 코드가 복잡하고, 안전성, 성능도 제대로 보장 못 해주는 STL을 이렇게까지 꼭 알아야할까? 꼭 이걸 써야할까?
항상 STL을 그냥 커스텀한 자체 STL 자료구조를 한번 각잡고 만들고 이를 유지보수하는게 가장 좋지 않을까하고 생각한다. 대 AI시대에서 이미 완성된 회사의 SaaS를 대체하는 생각보다는, 오히려 이런걸 직접 간단하게 만드는게 이전보다 훨씬 비용이 싸지않을까?
위의 shared_ptr은 직접 만들어보려고한다면 당연히 고려하게 되는 부분이다.
다른 것들도 흥미 본위로 한번씩 뜯어보긴한다만, 편하게 가져다 쓰라고 만들어놓은것들을, STL을 성능까지 끌어내서 사용하기위해, 이 복잡한 코드 구현부를 봐야하다는게 되는건 배보다 배꼽이 큰 것 같다.
결국 성능을 굉장히 따져서 쓸거라면, C++는 C와 같이 문법이 허허벌판인 STL의 대부분의 문법을 못쓰게 만든어버리고 C with Class로서가 가장 좋지않을까.
특히 C++만의 specific한 스펙은 딱히 다른 언어 base를 이해하는데 크게 도움 되지않는 경우가 대다수이기에 좀 더 그렇게 생각하는 것 같다.
PS : 26-03-23 : 멀티스레딩과 shared_ptr의 충돌 해결이라는 NDC2017년에 이미 공개적으로 퍼진 Known 이슈였다. 포스팅 제목조차 비슷하게….; 알았더라면 직접 뒤져가면서 찾아보진 않았을것같은데 아쉽
- https://ndcreplay.nexon.com/NDC2017/sessions/NDC2017_0093.html#k%5B%5D=%EC%A0%95%EB%82%B4%ED%9B%88
참고 자료
- https://github.com/megayuchi/ppt/blob/main/docs/- 2018_1128_shared_ptr%2C%20weak_ptr%EC%9E%91%EB%8F%99%EB%B0%A9%EC%8B%9D%20%EB%82%B4%EB%B6%80.pdf
- https://3dmpengines.tistory.com/2228
- https://openmynotepad.tistory.com/90
- https://3dmpengines.tistory.com/2229
- https://agh2o.tistory.com/45
- https://ria9993.github.io/cs/2022/09/28/shared-ptr.html
- https://ria9993.github.io/cs/2022/09/26/cache-coherence-bottleneck.html
- https://ria9993.github.io/cs/2023/03/22/race-condition-atomic.html
- https://learn.microsoft.com/ko-kr/cpp/cpp/how-to-create-and-use-shared-ptr-instances?view=msvc-170
- https://learn.microsoft.com/ko-kr/cpp/standard-library/memory-functions?view=msvc-170#make_shared