
miniRT
raytracing 구현하면서 생긴 간단한 문제 해결안들/ 진행 내용이 난잡하지만 아까워서 올리는 글
용어 통일
origin : 어떤 물체의 원점.
direction : 방향벡터
근본적인 궁금증
3차원을 어떻게 화면(2차원)으로 표현이 가능할까?
- 어떤 3차원 공간이 존재
- 물체들을 3차원 정보들로 표현
- ex : 구 원점 (4,5,3) r = 7 이거를 object list로 가지고 잇음
- 물체들을 3차원 정보들로 표현
- 우리의 화면을 담당해주는 Cam이라는 object가 존재 이 또한 3차원 공간에 존재 이 cam은 우리의 눈이라고 생각하면 된다.
- 이 Cam은 위치와 방향벡터를 가지고있음 우리의 화면은 cam 위치에서 방향벡터 방향으로 보는 화면을 띄우는 것이다.
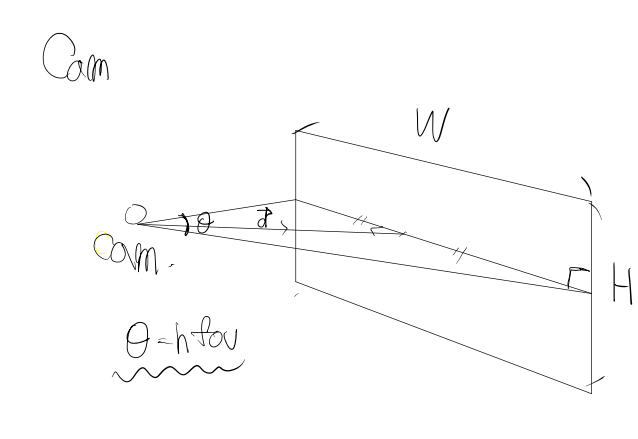
- Q 위치도 나왔고 방향도 나온걸 알겠다 그럼 보여줄 화면의 위치를 어떻게 정하는가?
- A : 그렇기에 FOV(field of view)라는게 존재한다. 이를 통해 확정
HFOV(Horizontal FOV)
좌표계 변환
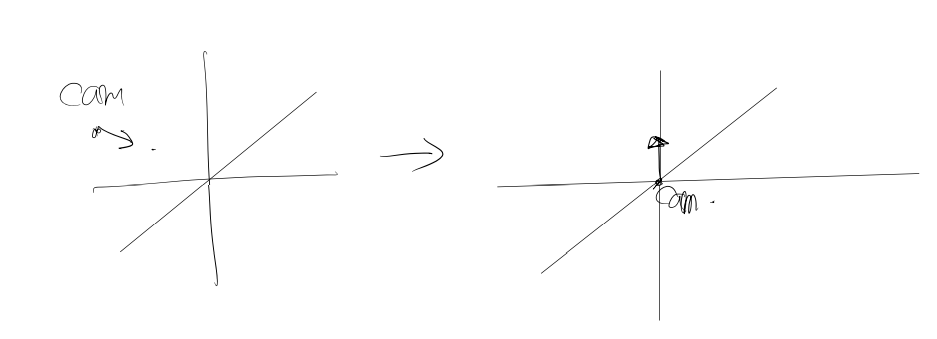
ray 생성을 편하게 하기위해서 cam의 시점을 원점, 방향을 (0,0,1)되도록 설정해주었다
이에 따라 빛, 물체 모두 맞춰서 변환해준다.
이후 cam이동이 있을때마다 이동후 캠이 0,0,0이되도록 다시 맞춰준다.
이렇게하면서 처음 계산할 ray들의 좌표가 간단해지는 장점이 있는다
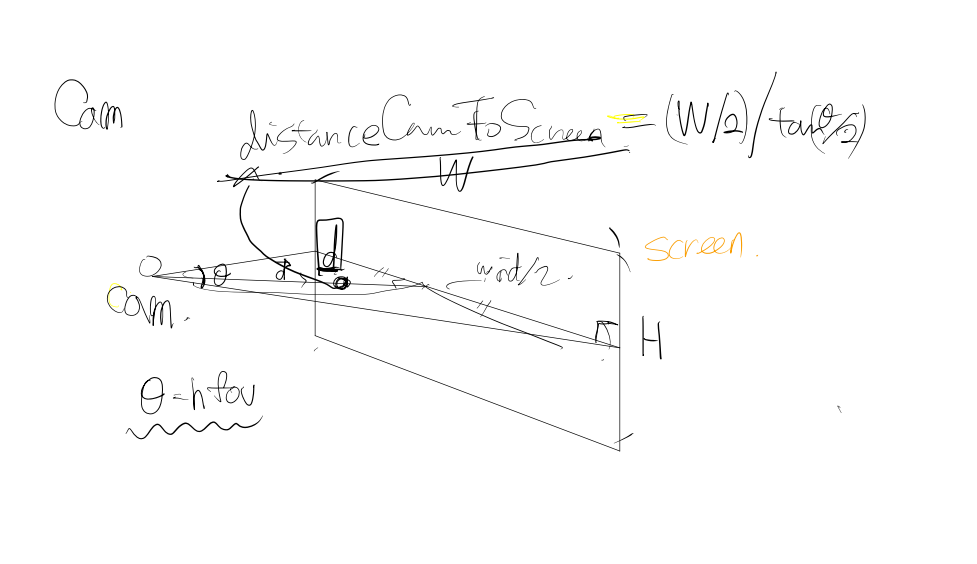
캠과의 거리는 다음과 같이 구할 수 있고 이를 그대로 z좌표에
x, y는 각각 WIDTH, HEIGHT에 맞춰서 좌표를 설정해주면 RAY의 origin이 완성 된다.
direction은 cam의 direction(0,0,1)을 그대로 사용한다.
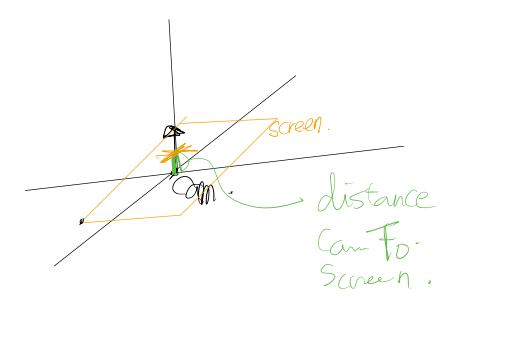
빛 처리
오브젝트 처리
object구조체로 vtable을 구현해 다형성 구현
→ quadrics로 엎어버림
물체의 충돌 판단
ray가 object와 충돌 판단을 하고 2차식을 풀어서(근의 공식 사용) 나온 t의 값이 실제 object와 충돌하는지를 판단해야한다.
일단 t는 양수여야한다. (음수라는건 origin에서 direction 반대방향으로 쐈을때 만난단 의미)
거리가 가까운것만 고른다면 이런 실제로 충돌하지 않는 점을 고를 수가 있다.
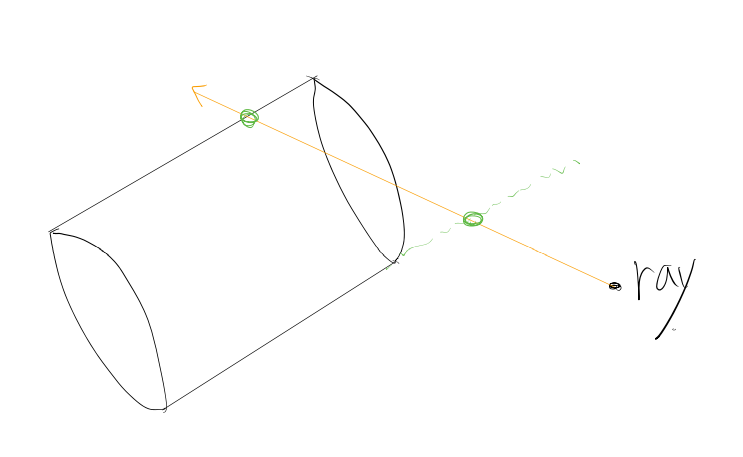
이 경우 충돌판단은 다음과 같이 한다.
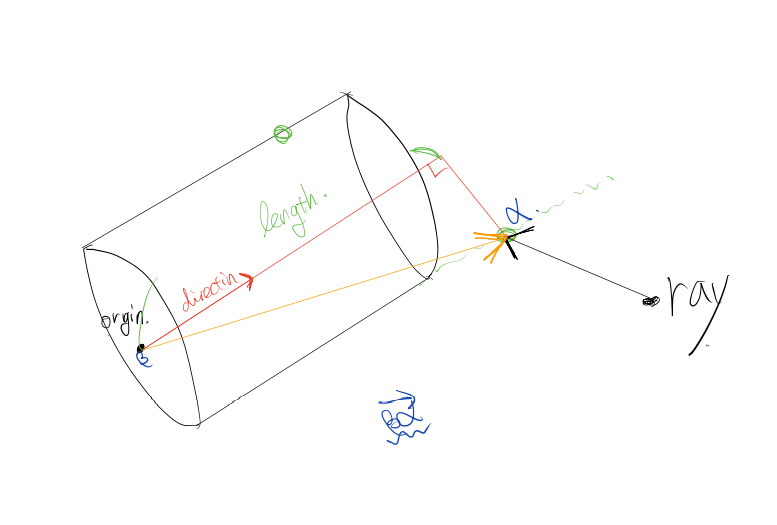
계산을 하고 나온 값 만큼 ray의 direction을 곱하고 ray의 origin을 더해주면 충돌지점 $\alpha$의 좌표(벡터)값이 나온다.
$\alpha$에 object의 origin을 빼면 $\vec{\beta\alpha}$ (주황색)가 나온다. 그럼 이 벡터와 object의 normalized 된 direction을 내적하면 length의 값이 나온다.
이 length의 값이 height 범위에 들어가는지를 판단함으로 충돌판단을 할 수가 있다.
질문들
- 행렬변환 구하는 과정
- 쿼드릭스 행렬 표현 방식
- 표면 노말벡터 어케구해여??
Phong Reflection Model (퐁 모델)
miniRT 노말맵, 매핑
obj의 dir default로 들어오는 값은
(0, 0, 1) 이다.
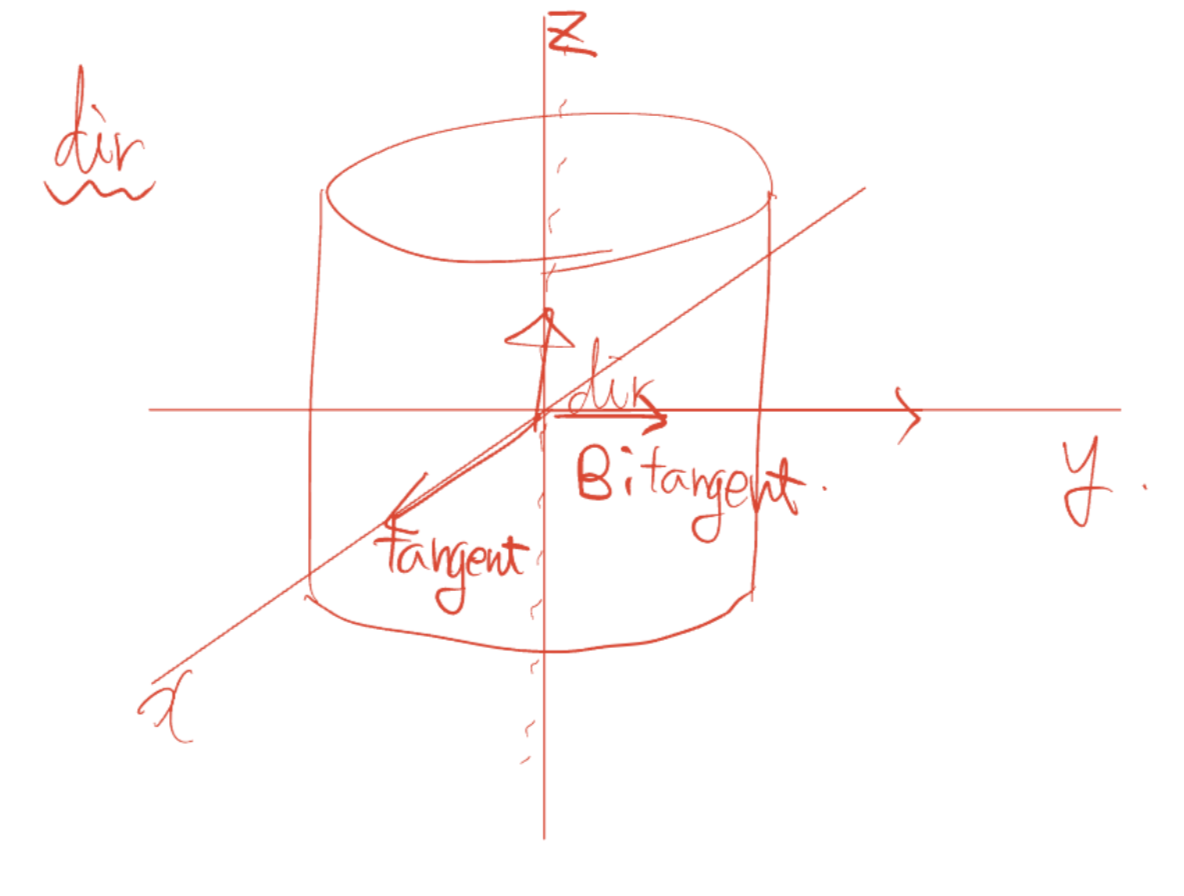
이를 토대로 tangent vector를 구하는데 이제 여기에 일반적으론 (0,1,0)과 외적을 통해서 값을 계산한다.
tangent vector
1
2
3
4
5
6
7
8
9
10
11
//탄젠트 벡터. 단단순히 0,1,0 을 외적해서 구함.
//quad dir 방향
static t_vec4 get_quad_tangential(const t_vec4 *unit_normal)
{
if (unit_normal->y == 1)
return ((t_vec4){1.0f, 0.0f, 0.0f, 0.0f});
else if (unit_normal->y == -1)
return ((t_vec4){-1.0f, 0.0f, 0.0f, 0.0f});
else
return (v3_normalize(v3_crs(make_v3(0, 1, 0), *unit_normal)));
}
적당하게 (0,1,0)을 외적한 값을 tangent vector로 세팅 (dir에 수직인 벡터로서 의미를 가짐.)
default에서 계산되는 값은 (1,0,0)
texture
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
t_color get_texture_color(const t_quadrics *Q, \
const t_xpm *texture, \
t_vec point)
{
float local_pnt[2];
int pixel[2];
if (texture->img.img == NULL)
return (Q->color);
else if (Q->type == Q_PLANE)
return (get_plane_texture_color(Q, texture, point));
t_vec3 originToHitPoint = v3_sub(point, Q->org);
{
// 0 divide error
local_pnt[1] = (v3_dot(originToHitPoint, Q->dir) - Q->range_z[0]) / (Q->range_z[1] - Q->range_z[0]);
local_pnt[1] *= texture->img_height;
pixel[1] = ((int)local_pnt[1] % texture->img_height);
pixel[1] = texture->img_height - pixel[1] - 1;
//이미지 반반전전
}
{
t_vec3 projectionVec = v3_crs(Q->dir, v3_crs(originToHitPoint, Q->dir));
//
const t_vec3 binormal = v3_crs(Q->dir, Q->tan);
local_pnt[0] = atan2f(v3_dot(projectionVec, binormal),v3_dot(projectionVec, Q->tan))
* 180 / M_PI + 360;
local_pnt[0] = fmodf(local_pnt[0] + 360, 360);
// 양수로 치환
local_pnt[0] = local_pnt[0] / 360 * (texture->img_width);
pixel[0] = ((int)(local_pnt[0])) % (texture->img_width);
}
return (get_image_pixel_color(&texture->img, pixel[0], pixel[1]));
}
- 대치 시킬 height 구하기.
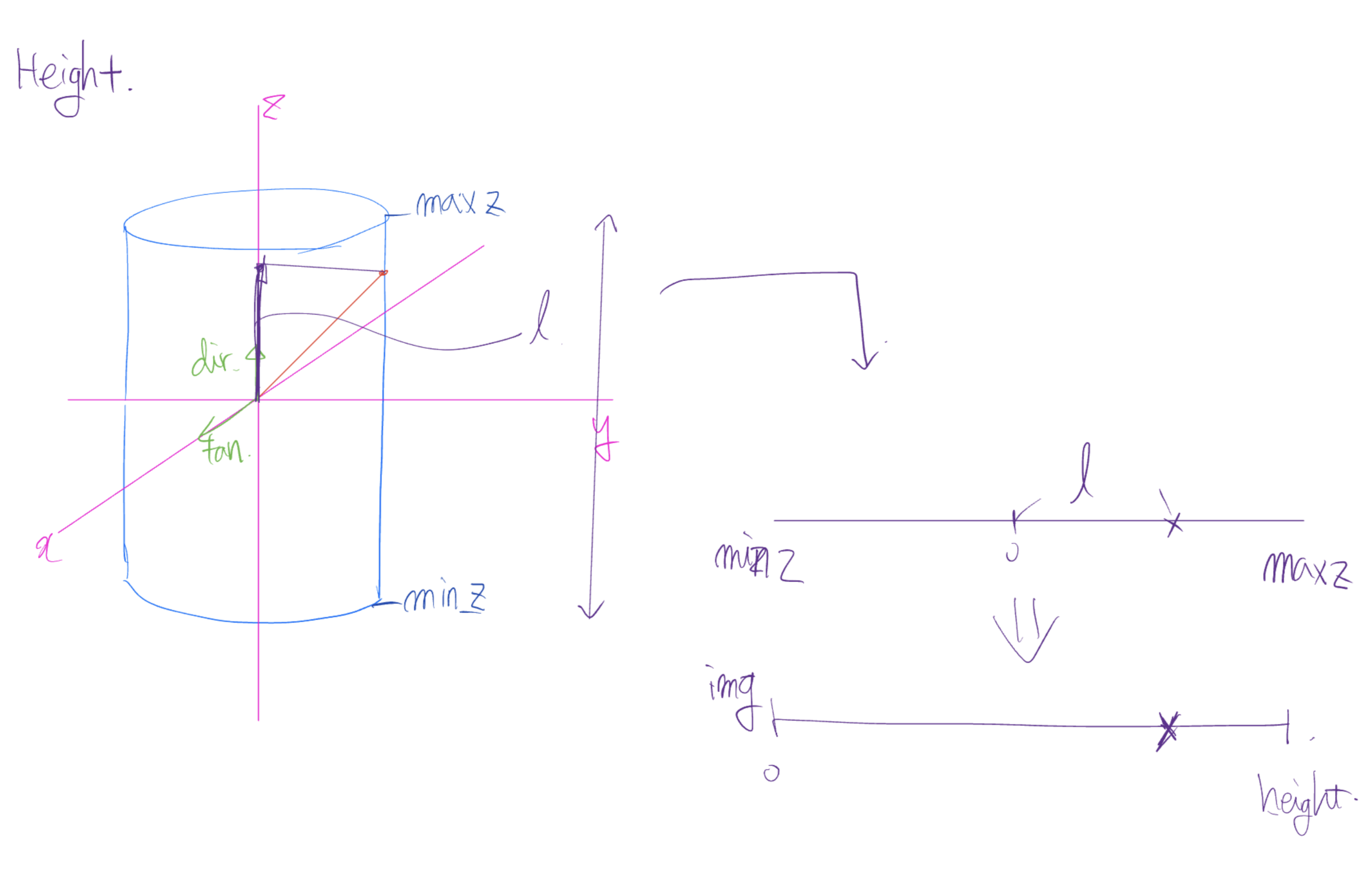
기본적인 아이디어는 origin에서 표면까지의 벡터를 dir(default는 0,0,1이기에 Z축)에 사영시키고 그 사영시킨 길이를 토대로 height에 대치 시킨다.
mlx에서의 이미지가 뒤집어지기때문에 마지막에 인덱스를 뒤집어줬다
- 대치시킬 width구하기

origin에서 표면까지의 벡터를 dir을 법선벡터로하고 origin을 포함하는 평면에 사영시키고(default일때 dir은 0,0,1이고 origin은 0,0,0으로 xy평면)
x축으로부터의 양의 방향으로의 각도를 기준으로 width에 대응 시킨다.
이때 평면에 사영시킨 벡터를 구하는 방법으로는 dir벡터와 두번 외적을 함으로 구할 수 있다.
normal map
텍스쳐에서 값을 뽑아 온다.
- 여기 뽑아온 값은 RGB값이니 이를 -1 ~ 1 범위로 scaling 해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
static t_vec3 apply_normal_map(const t_quadrics *Q, \
t_vec3 hit_point, \
t_vec3 normal)
{
t_color color;
t_vec3 bump_vec;
t_vec3 temp_normal[3];
if ((Q->textures[T_NORMAL]).img.img == NULL)
return (normal);
//1.
color = get_texture_color(Q, &Q->textures[T_NORMAL], hit_point);
{
bump_vec = make_v3((float)color.red, (float)color.green, (float)color.blue);
bump_vec = v3_mul(bump_vec, (float)2 / 255);
bump_vec = v3_sub(bump_vec, make_v3(1, 1, 1));
// pixel 0 ~ 255 -> -1 ~ 1
}
// 2.
t_vec3 u = v3_normalize(v3_crs(Q->dir, normal));
if (v3_isnull(u) == TRUE)
u = Q->tan;
t_vec3 v = v3_normalize(v3_crs(normal, u));
// 3.
temp_normal[0] = v3_mul(u, bump_vec.x);
temp_normal[1] = v3_mul(v, bump_vec.y);
temp_normal[2] = v3_mul(normal, bump_vec.z);
normal = v3_add(temp_normal[0], temp_normal[1]);
normal = v3_normalize(v3_add(normal, temp_normal[2]));
return (normal);
}
- UV 벡터를 구한다
여기에선 적당하게 dir값과 normal를 외적하여 normal에 수직인 u(여러 normal에 대해서 불변한 값인 dir과 외적을 하면서 일관적인 u, v를 구함)를 구하고 u와 normal을 다시 외적하여 v를 구한다.
- 그러면 최종적인 normal 값은 = n * z + u * x + v *y
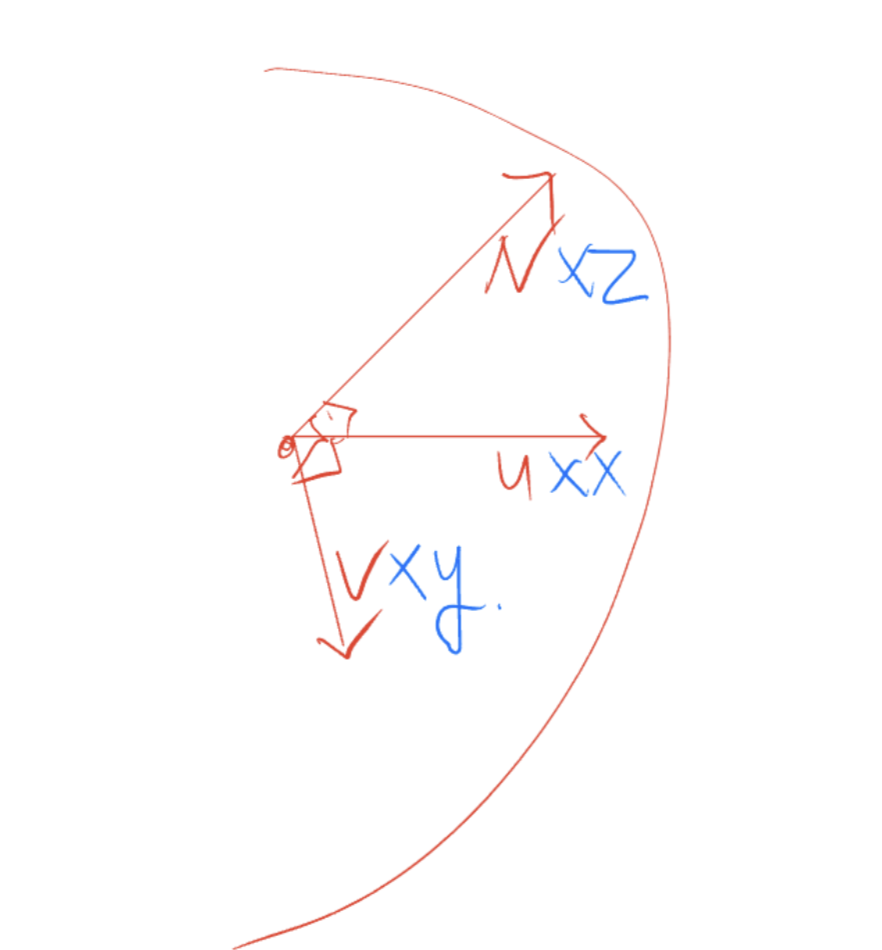
UV 탄젠트 벡터에 대해서 정확한 개념을 알고하는게아니라 방향이 틀렸을 수 있습니다.
부동소수점비교
부동소수점 값이 같지 않을 수도있다는거는 기본
EPSILON 사용
개발 중 겪은 것들
협업
기본적으로 각자 branch를 따서 진행함.
나 같은 경우는 간단간단한 코드 수정 같은 경우는 굳이 branch 따지 않고 진행함.
근데 이제 크게크게 엎어야하거나, 수정사항이 여러곳에 걸쳐서 딱봐도 충돌이 심하게 날것같은 수정은 branch를 무조건 파서 진행함.
이제 처음에 오브젝트들마다 struct가 다 있었고 다형성으로 묶기 예뻐보여서 C언어지만 함수포인터 이용해서 객체지향을 구현 해버림 → 이후에 쿼드릭스 도입하면서 구조 엎어짐
한번 분기점을 정해서 거기까지 개발 쭉 한다음에
거기서부터 설계도 고치고 시간 찍어가면서 최적화도하고 진행해버림
나같은 경우는 구조체하나가 너무 무거워보여서 분리해야겠는데? 하면서 분리하고
코드 느린부분 보면서 계속 개선안 생각하고 그러면서 코드도 고치고 등등..
버그
초기화되지않은 것 사용해서 생긴 버그 → 실행할때마다 결과가 다르게나옴
3차원 벡터 → 확장성을 위해 4차원 벡터로 옮기면서 w인자의 값이 초기화가 제대로 안되서 생긴 문제였음.
3차원 벡터만을 사용하다 4X4 행렬을 사용하면서 생긴 문제.
미리미리 assert 사용을 많이 했으면 고칠 수 있었을텐데
floating 정밀도 문제
점박이 : 특정 픽셀에서 값이 튀는 현상이 발생함 해당 좌표를 직접 찾기도 힘들어 디버깅하는 것이 굉장히 힘들었었음
→ pixel color를 구현 마우스로 해당 점을 클릭했을때 해당 위치로 ray를 쏴 계산되는 값 정보를 띄우도록 만듬
성능최적화
하나의 ray 계산을 픽셀마다하니 최소 O(WH)만큼의 연산이 걸린다. 1920 * 1080이면 2073600 약 200만 번의 연산을 최소 한다.
KD- tree (구현 x)
ray가 오브젝트에 실제로 닿았는지를 판단하기위해 모든 오브젝트와 ray와 충돌 연산을 했어야함 이부분에서 굉장히 시간을 많이 잡아먹음. → 아 이 계산하는 오브젝트 수를 줄일 수 없을까?
최적화 고려사항 중 하나 이거 결국에는 구현 못함.
SIMD
- 메모리 align에 대한 이해 필요.
아이디어로서 union을 사용해 바로 simd를 바로 사용가능하게 타입을 맞춰주었다
그러고 intrinsic을 사용했는데 결과적으로 10%정도 더 느리게 나왔다.
어셈을 까보니 intrinsic을 사용하기 전후로 왜 들어갔는지 모를 어셈이 잔뜩 추가가 되면서 결과적으로 simd를 사용하지 않는 코드보다 명령어 라인자체가 더 길게 나오더라
벡터 명령어 자체도 기본 명령어가 상대적으로 클럭이 떨어지는데 그게 더 길게 어셈코드가 있으니 당연히 더 느려지는게 맞다.
원인은 못 찾음
최적화
time stamp를 찍으면서 최적화 작업을 수행
단순히 mlx를 초기화하는데만 300ms정도가 소모 (불변값)
O(WH)만큼 ray를 쏘는 rendering부분이 가장 시간을 많이먹는 코어 부분 → 이부분의 성능을 올려보자
- -O2 : 단순히 이 부분만 적용했을 때 30% 정도의 시간이 감소
- double → float , double 3개짜리 구조체 였던 벡터를 4개짜리로 바꿔 simd최적화 유도. 벡터 연산의 덧셈, 뺄셈을 직접 compile intrinsic을 이용해 simd 최적화 : → 여기서도 30%정도 시간을 줄임
- 멀티쓰레딩 : 화면을 4분할하여 각 ray 계산 각각 독립적으로 계산을 하기에 경쟁상태가 일어나지 않음 → 해당 부분 거의 1/4로 줄어듦.
- 파이프라인 효율을 올리기위해 코어 파트의 if문 분기를 줄임. 10%미만
- 로직상 중복되는 부분 줄임 : 전체 코드에 대한 이해가 필요함 ⇒ 40% 향상
- c refection 의 diffuse, specular 부분에 대해서 각각 도는 반복을 합칠 수 있기에 이 부분 로직을 합쳐버림 → 30% 정도 성능 향상
object 충돌
하나의 ray에 대해서 충돌하는 object를 구하는 함수가 있는데 이 부분이 프로젝트 전체에서 가장 많이 호출되는 함수이다.
하나의 ray에 대해서 모든 object와 충돌비교를 하고 충돌할시에 가장 가까운 object를 골라 업데이트를 해야한다.
O(numObject)의 시간복잡도에 무거운 행렬 연산, 각종 float 이차방정식 해를 구하는 각종 연산이 들어가면서 굉장히 무거운 함수인데 1000만번 가까이 호출하는 프로젝트 전체에서 가장 병목이 되는 부분이었다.
- singleton의 잦은 호출 정리 :
- → static 변수를 가지는 함수는 inline을 사용할 수 없음
- → 의도적으로 할수도 없고 따라서 컴파일 최적화를 할 수 없음. 호출을 최소화하고 많이 사용하는 경우에는 따로 변수에 담아서 사용
충돌판단개선
팀원의 아이디어
object 충돌판단시에 복잡한 연산이 들어가는걸 경량화 했다.
모든 물체를 포함하는 구라 고려하고 구와 ray가 접하는질 판단하고 가상의 원과 충돌할시에 세부적인 충돌 체크를 하는 것 이것만으로도 연산성능이 확실히 빨라져서 70%의 성능향상이 있었다.
profile
해당 코드를 cpp로 포팅하면서 VS에서 profile을 돌려보았다.
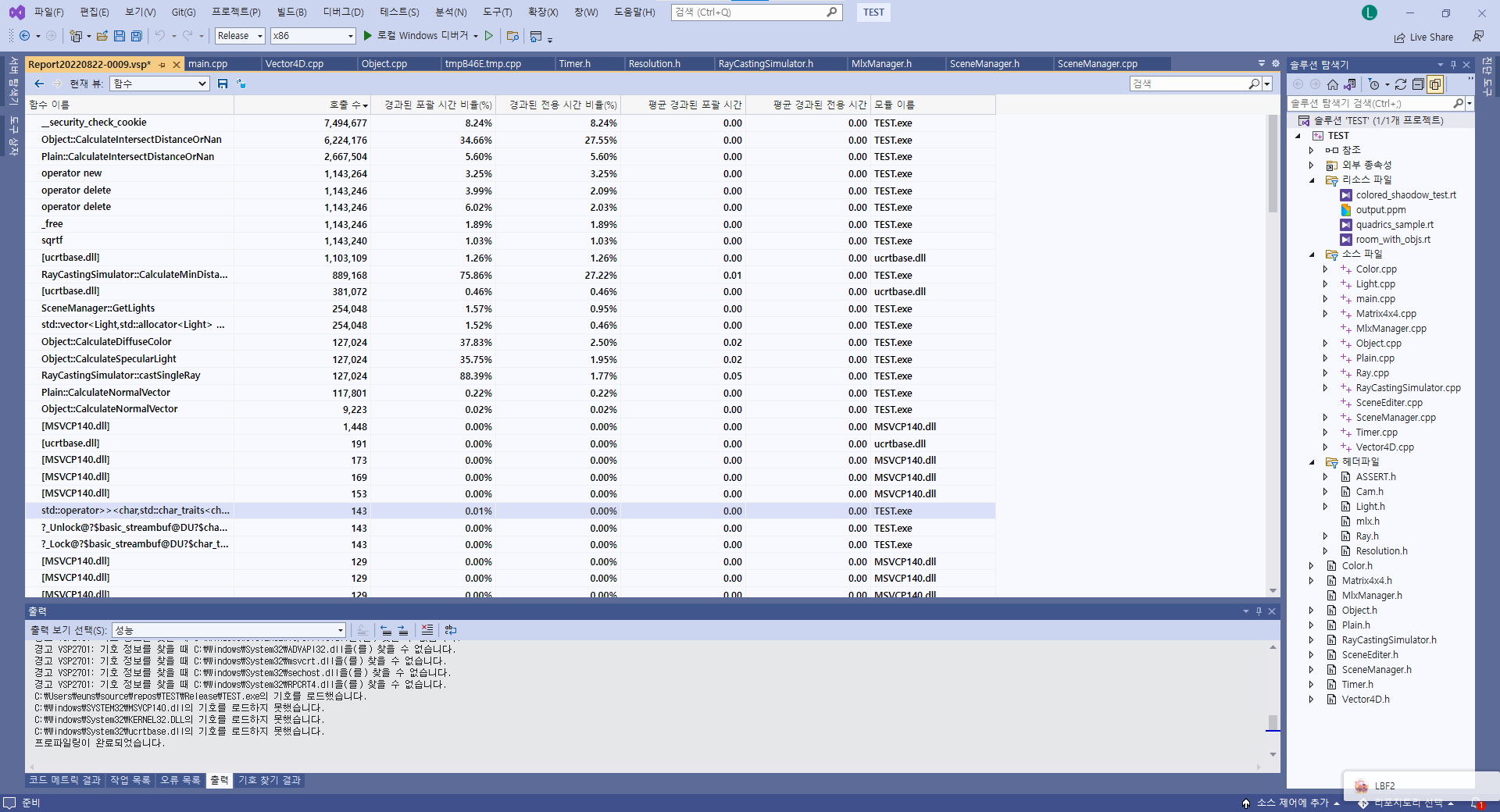
new delete를 백만번씩 호출하는게 보였다. 아마 SceneManager에서 GetLights, GetObjects를 하는데 아마 값반환으로 해서 최적화가 따로이루어지지 않은것같다 이부분은 레퍼런스 반환으로 바꿔줬다.
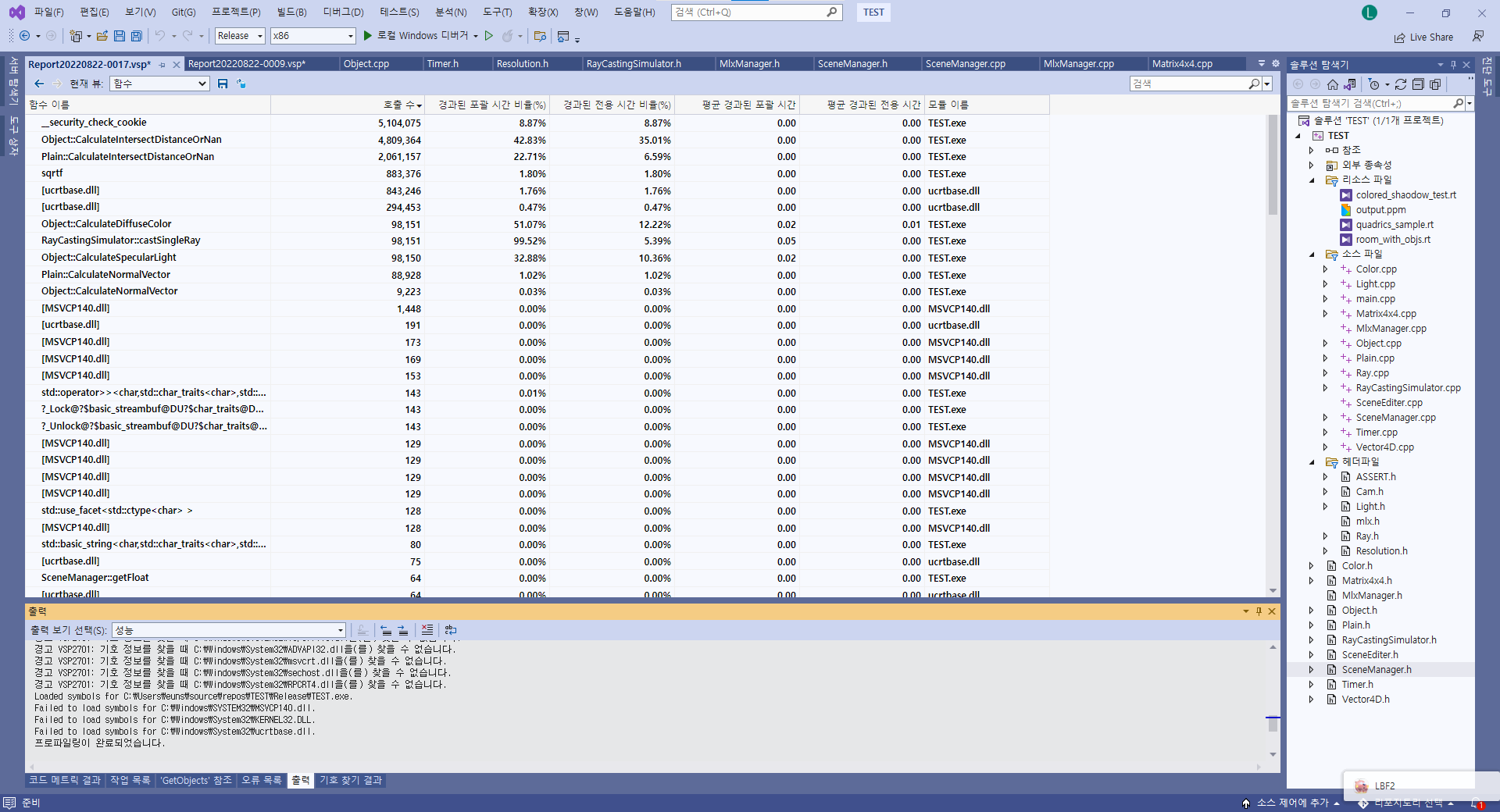
그다음은 security check cookie 차지하는 부분도 굉장히 크고 호출횟수가 압도적인데
아마 VS자체에서 옵션으로 잡아주는 것같다. 그러므로 이부분도 제거
GS Cookie라고한다.
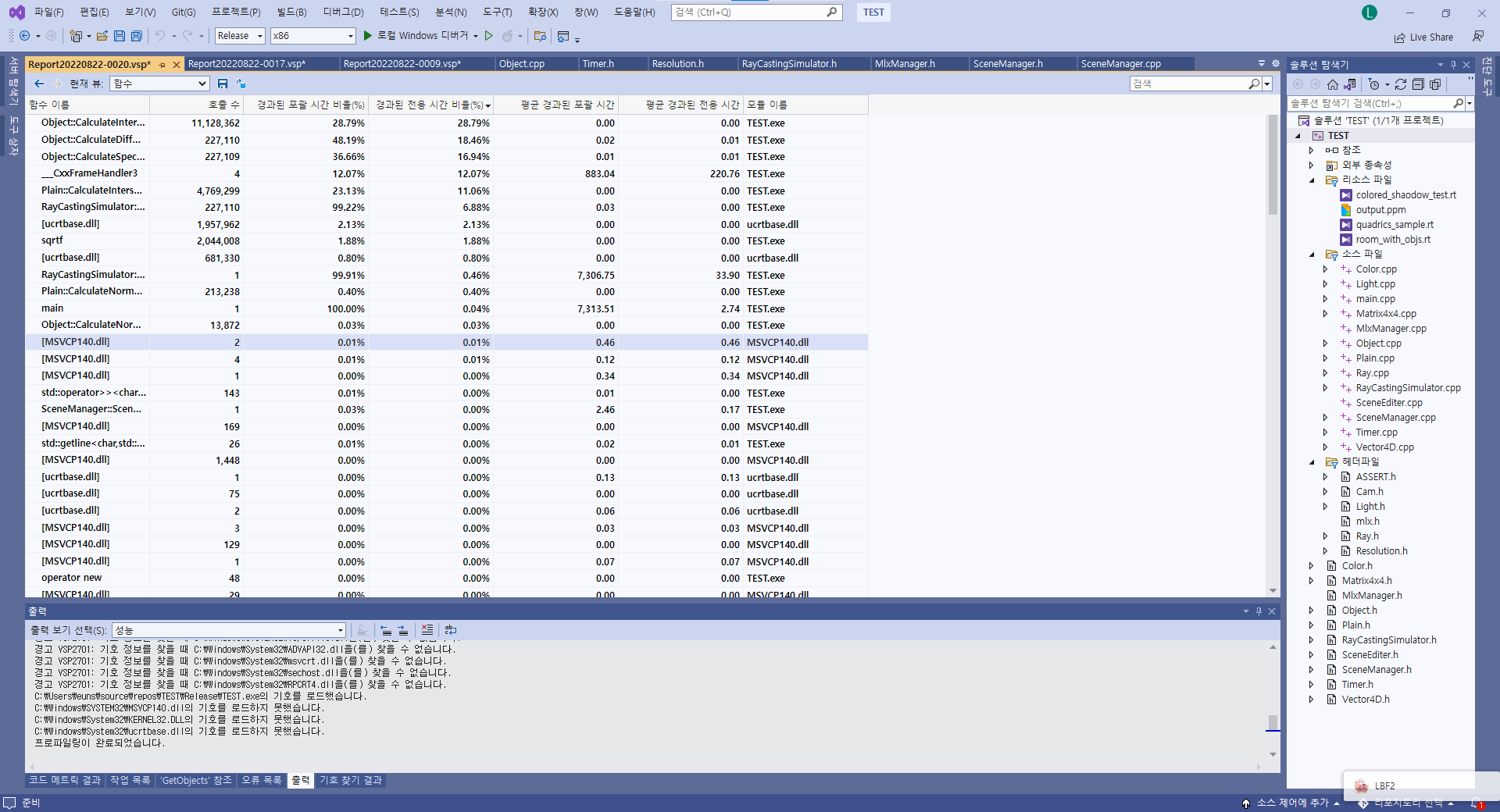
같은 코드 실행하는데 왜 실행할때마다 호출횟수가 달라지는 질모르겠다
이것저것 찾아보다
고급명령 집합 사용이라는 옵션을 찾게되었다
이를 사용하면 simd 명령어를 사용할 수 있다면 그쪽 명령어를 사용할 수 있게 최적화해주는 듯했다.
버전 AVX512까지 할 수 있었고 cpu사양마다 지원하는 버전이 달라서 이는 확인해봐야한다.
어지간한 5~6년된 cpu정도는 지원하고 사용하고있는 컴퓨터가 얼마나 오래됐더라도 SSE 2정도는 다 지원한다고 봐도된다.
이를 clang에서도 사용할 수 있나 찾아보니 나온것.
AVX512는 최신의 내 노트북에선 작동했으나 6~7년 정도 된 데스크탑에서는 illegal instruction이라는 에러와 함께 실행이 뽀개졌다 이 부분은 위에 설명했듯이 옵션를 조금 옛날것으로 바꾸는 것만으로 해결된다.